해당 게시물은 Standford 2017 CS231n 강의를 들으며 정리한 내용이며 슬라이드를 바탕으로 작성되었습니다.
CNN Architectures
- Case Studies
- AlexNet
- VGG
- GoogLeNet
- ResNet
- Also…
- NiN(Network in Network)
- WideResNet
- ResNeXT
- Stochastic Depth
- DenseNet
- FractalNet
- SqueezeNet
Review : LeNet-5
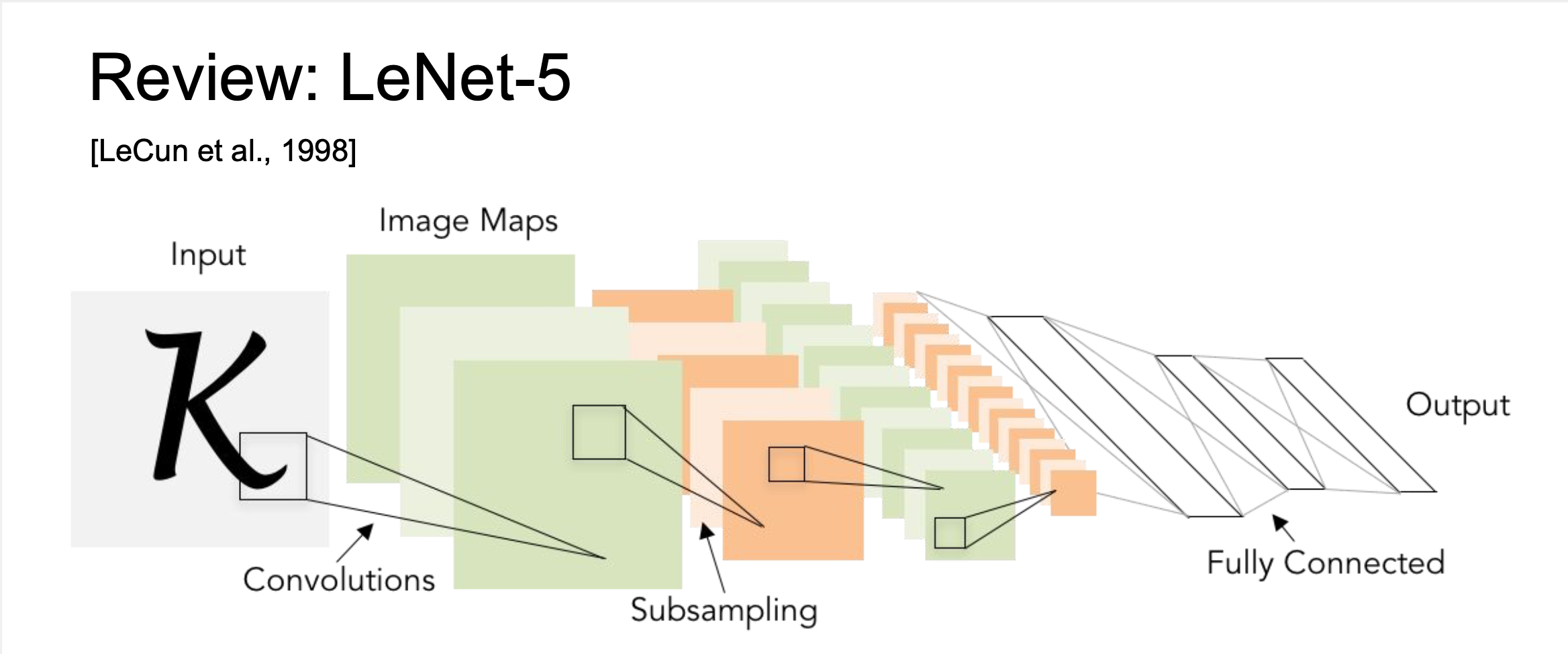
- LeNet-5
- 산업에 아주 성공적으로 적용된 최초의 ConvNet
- 이미지를 입력으로 받아서 Stride = 1, 5X5 사이즈의 필터를 사용하여 Conv, Pooling, FC 레이어를 거치는 모델 → 단순하지만 숫자 인식 부분에서 좋은 성능을 보여준다.
AlexNet
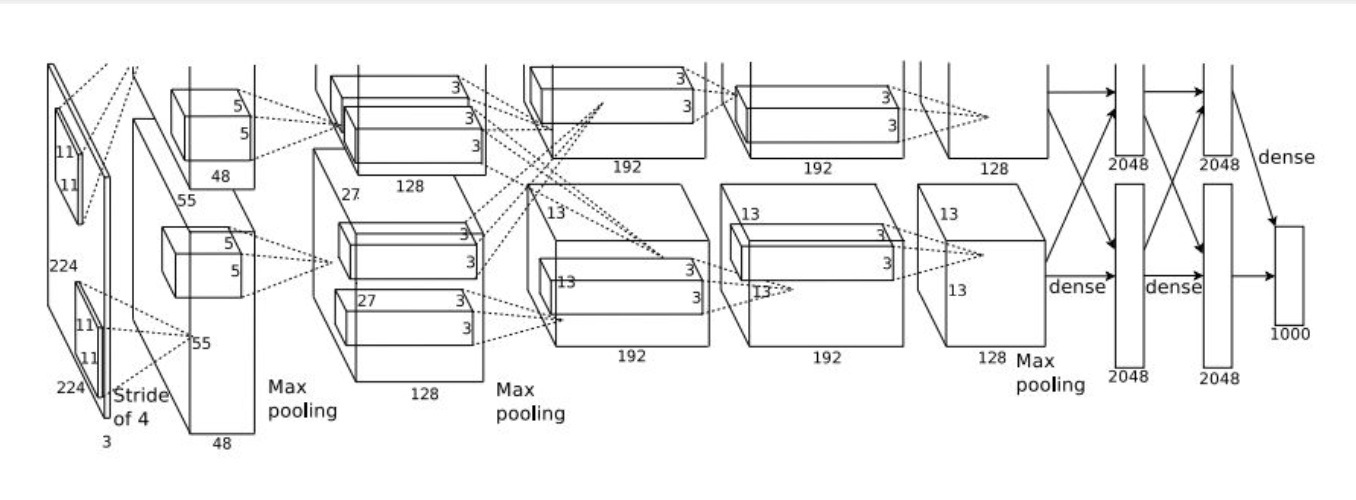
- 2012년에 등장한 최초의 Large Scale CNN이며 Imagenet Classification Task를 잘 수행했다.
- AlexNet 의 등장으로 ConvNet 연구의 부흥을 일으켰다.
- Conv - Pooling - normalization 구조가 2번 반복된다.
- 기존 LeNet과 유사하지만 Layer가 늘어났다.(5 Conv Layer, 2 FC Layer)
- Details/Retrospectives
- ReLU를 처음 사용
- Normalization layers를 사용(요즘에는 잘 쓰이지 않는다)
- 많은 data augmentation을 사용(flipping, jittering, color norm 등등)
- dropout 0.5
- batch size 128
- SGD Momentum 0.9
- LR 1e-2로 초기 설정하고 val accuracy가 올라가지 않는 지점에서 학습을 종료하고 그전까지는 LR을 1/10씩 줄여서 1e-10까지 줄였다.
- L2 weight decay 5e-4
- Ensemble 이용
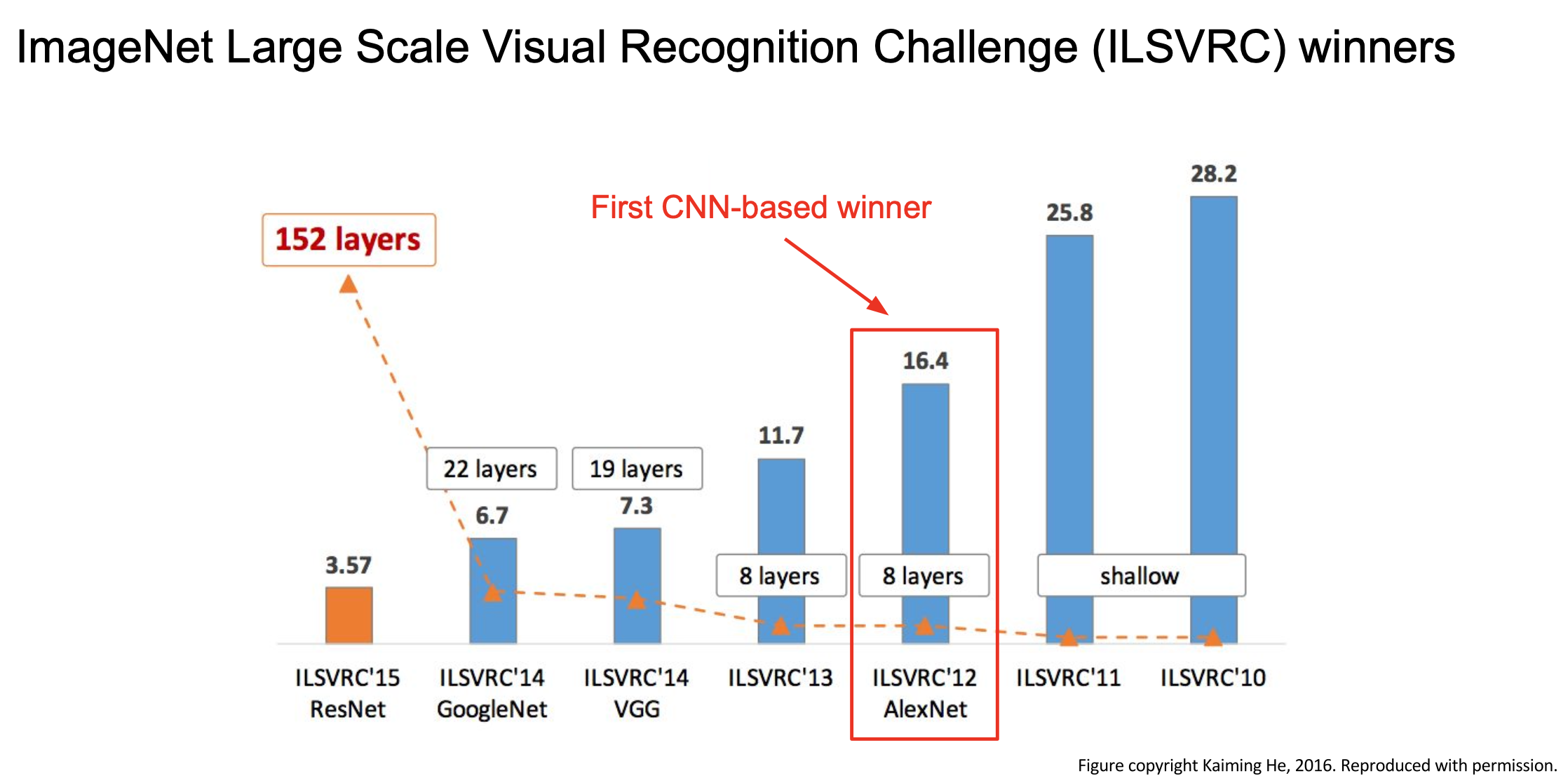
- AlexNet 은 최초로 CNN을 이용해 우승한 모델이다.
- 이전과는 완전히 다른 Deep learning과 Conv Net을 이용한 접근이 좋았다고 평가 받는다.
- 이후 다양한 Task의 Transfer learning에 많이 사용되었다.
ZFNet

AlexNet과 레이어수, 구조는 같지만 Stride, 필터 수 같은 하이퍼 파라미터를 조정해서 성능을 향상했다.
VGGNet
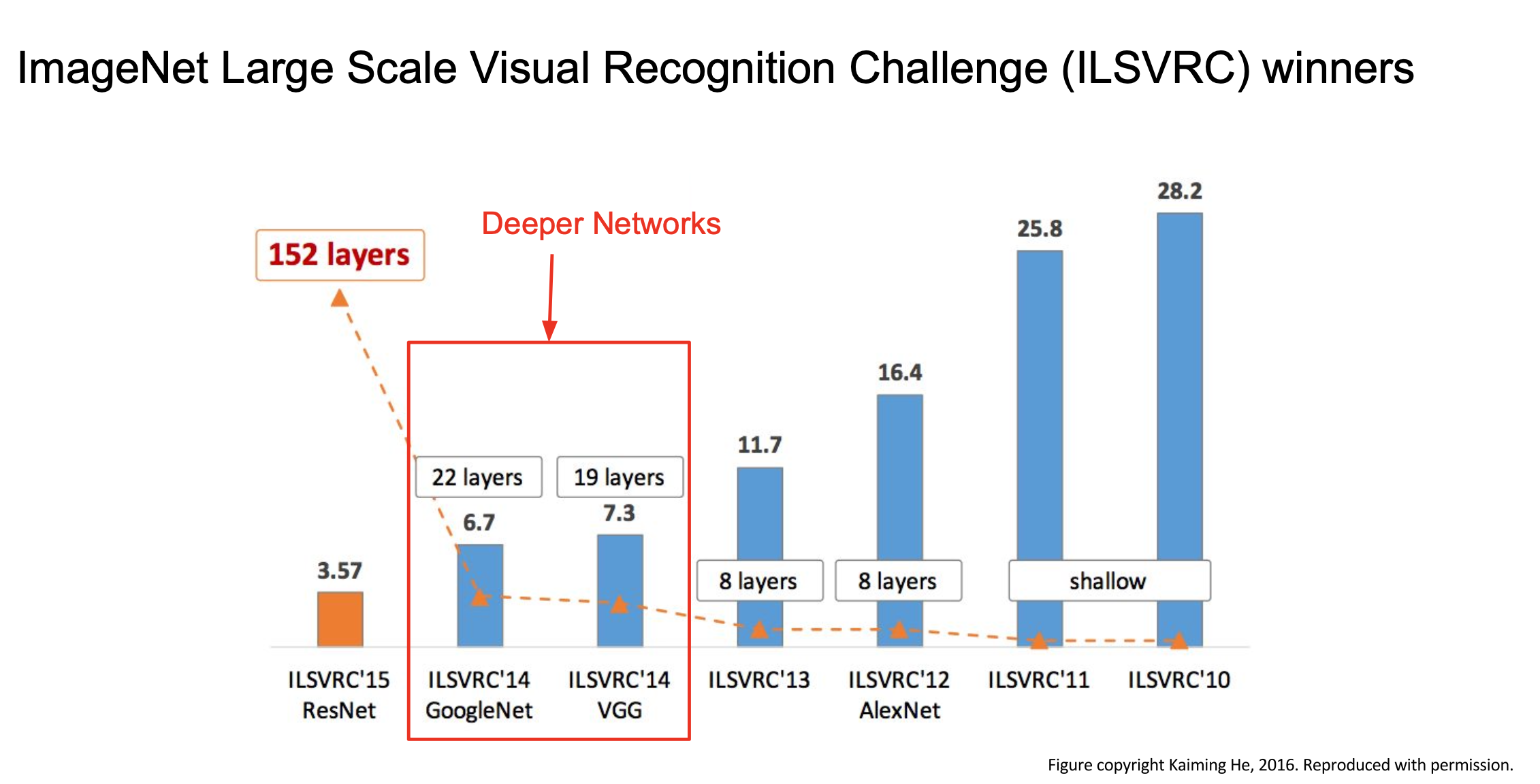
GoogleNet과 VGGNet이 이전의 모델들과 가장 다른 점은 네트워크가 훨씬 깊어졌다는 것이다.

- VGG는 구조는 간단하지만 아주 잘 만든 모델이다.
- AlexNet과 다르게 VGG는 3X3 크기의 필터만을 사용하였는데, 이는 이웃 픽셀을 포함할 수 있는 가장 작은 사이즈의 필터가 3X3사이즈이기 때문이다.
왜 굳이 작은 필터를 사용했을까?
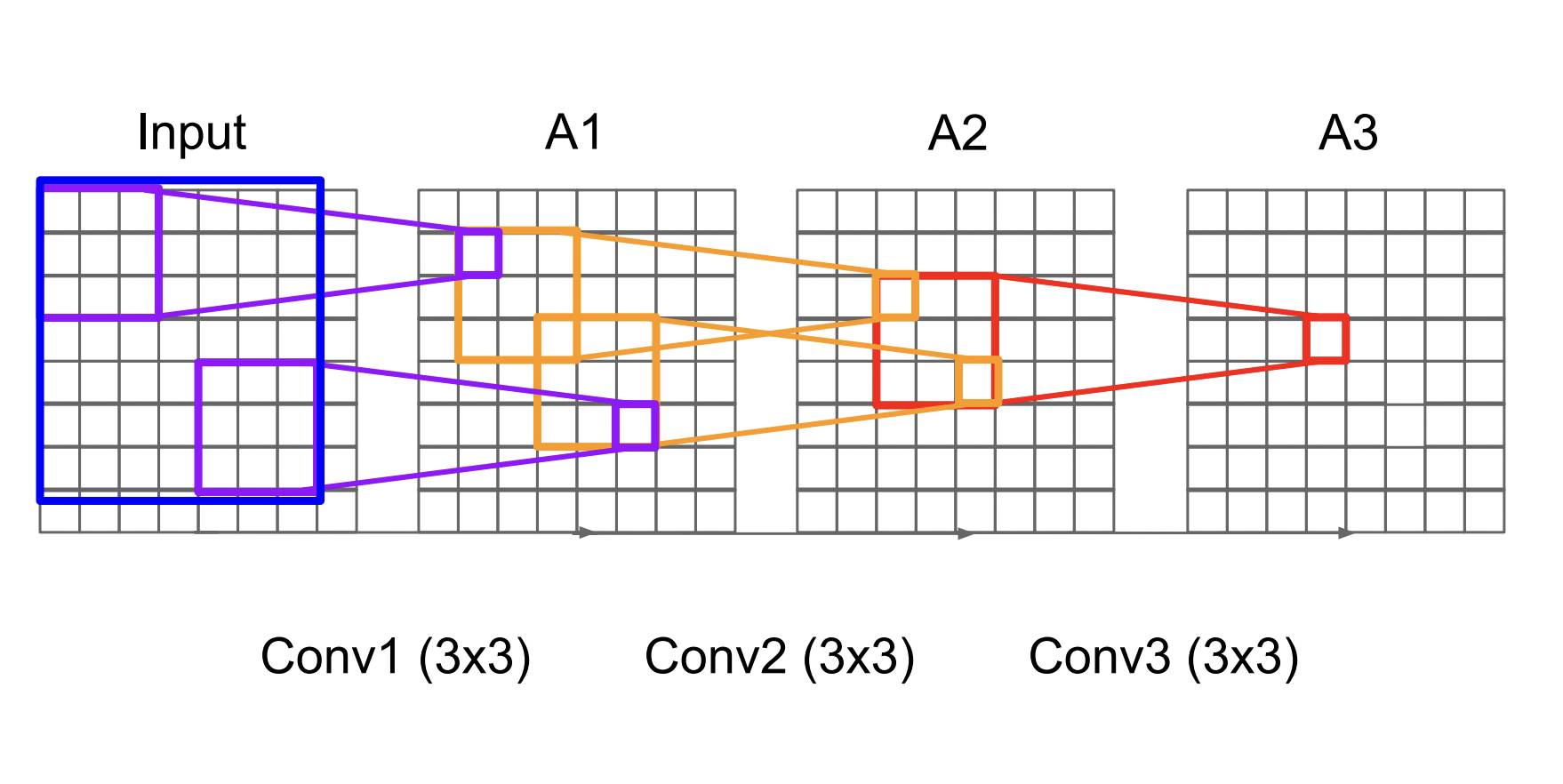
- 사이즈가 큰 필터에 비해 레이어를 더 많이 쌓으면서 파라미터수를 감소시킬 수 있다.
- 3X3 사이즈의 필터로 3번의 합성곱을 거치면 7X7 사이즈의 필터와 동일한 receptive field를 갖는다.
- 3X3 필터로 3번 연산할 때 파라미터 수 : $3*(3^2 C^2)$
- 7X7 필터로 한 번 연산할때 파라미터 수 : $7^2 C^2$
하지만 VGGNet은 너무 많은 파라미터와 메모리를 사용한다는 단점이 있다.
- Q. 네트워크가 깊다(depth)는 말이 필터를 말하는 것인지 레이어를 말하는 것인지?
- A. 레이어가 많다는 말이다. Depth에는 두 가지 의미가 있는데 첫 번째는 채널의 깊이를 의미하고 두 번째는 학습 가능한 가중치를 가진 레이어의 개수를 의미한다. 하지만 네트워크가 깊다는 얘기를 할 때는 레이어의 개수가 많다는 의미이다.
- Q. 왜 필터를 여러 개 사용하나요?
- A. 필터가 3X3사이즈를 가졌다고 가정하면, 하나의 필터는 3X3Xdepth를 보고 하나의 feature map을 만들게 된다. 그렇게 입력 전체를 돌면서 feature map을 완성하게 되는데, 이렇게 되면 여러 개의 필터들은 여러개의 feature map을 만들게 될 것이다. 이렇게 하나의 입력에서 서로 다른 여러가지의 패턴들을 인식하기 위해 필터를 여러개 사용한다.
GoogleNet
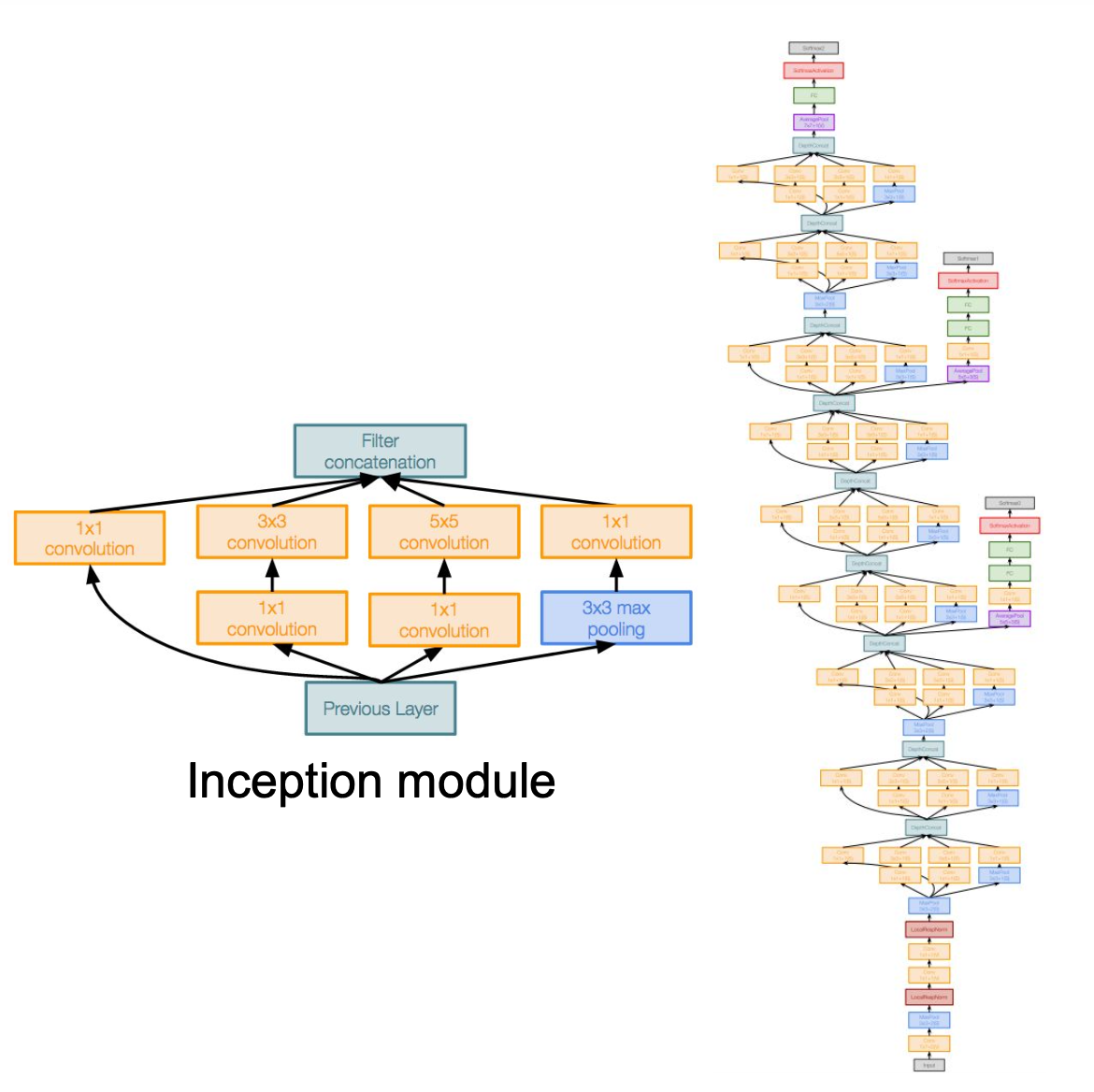
- GoogleNet은 효율적 계산에 대한 특별한 관점을 이용하여 계산을 아주 효율적으로 수행하도록 설계된 네트워크이다.
- 총 22개의 레이어로 구성
- Inception 모듈을 사용
- 파라미터를 줄이기 위해 FC layer를 사용하지 않았다. → AlexNet 파라미터의 1/12 정도 되는 5M 개의 파라미터가 있음

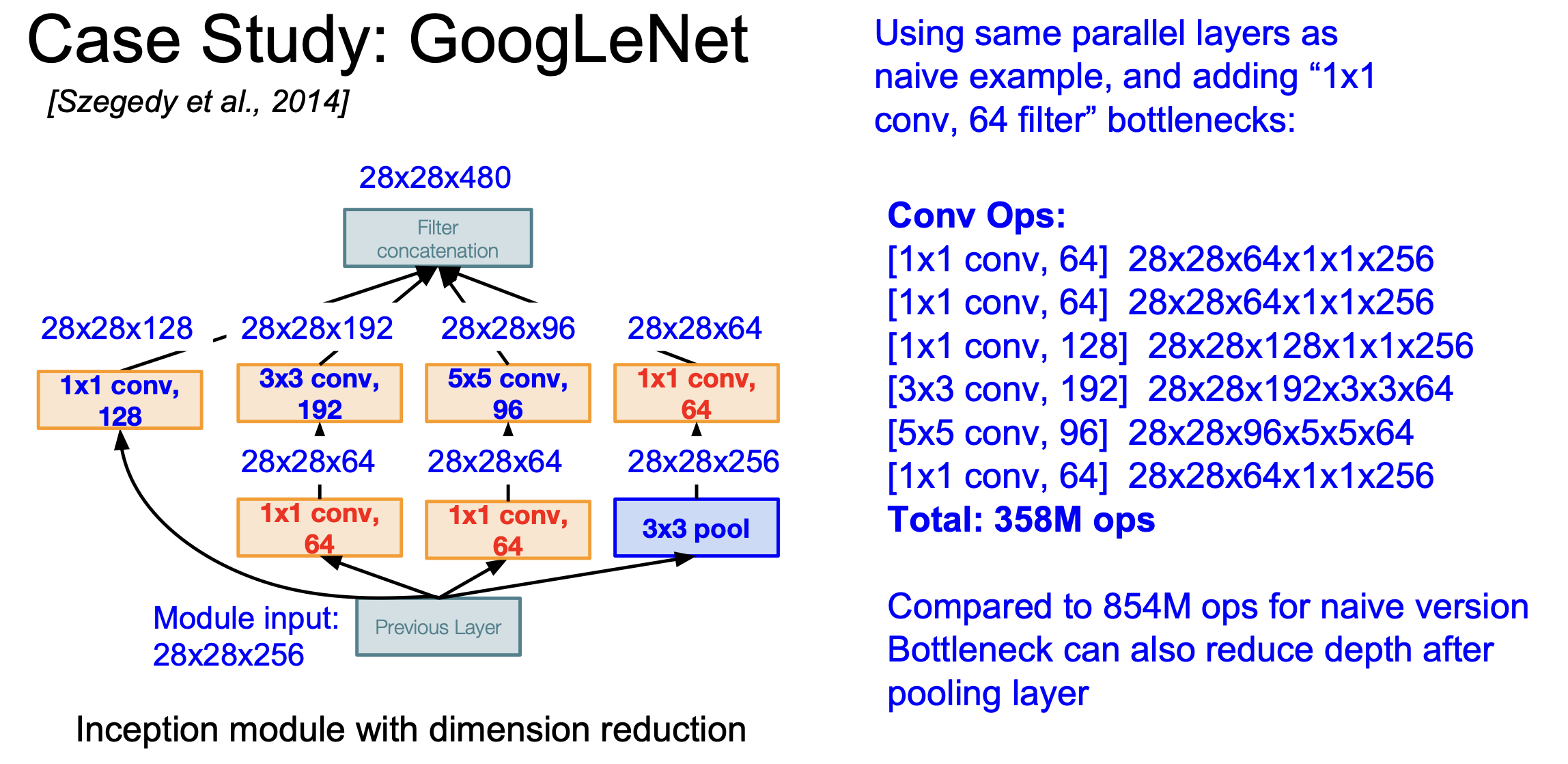
하지만 이런 Inception모듈에도 문제점은 발생한다. 위 사진처럼 간단한 모양의 Inception 모듈이 있다고 하자. 이때 Input size가 28X28X256이라면 총계산을 854M 번이나 수행해야 한다. 그리고 이런 모듈들이 쌓이게 되면 output의 depth가 계속해서 증가하기만 하기 때문에 굉장히 비효율적인 계산을 수행하게 된다.
이러한 문제점을 해결하기 위해서 1X1 convolution을 이용해 feature depth를 줄이는 Bottleneck layer를 이용한다.
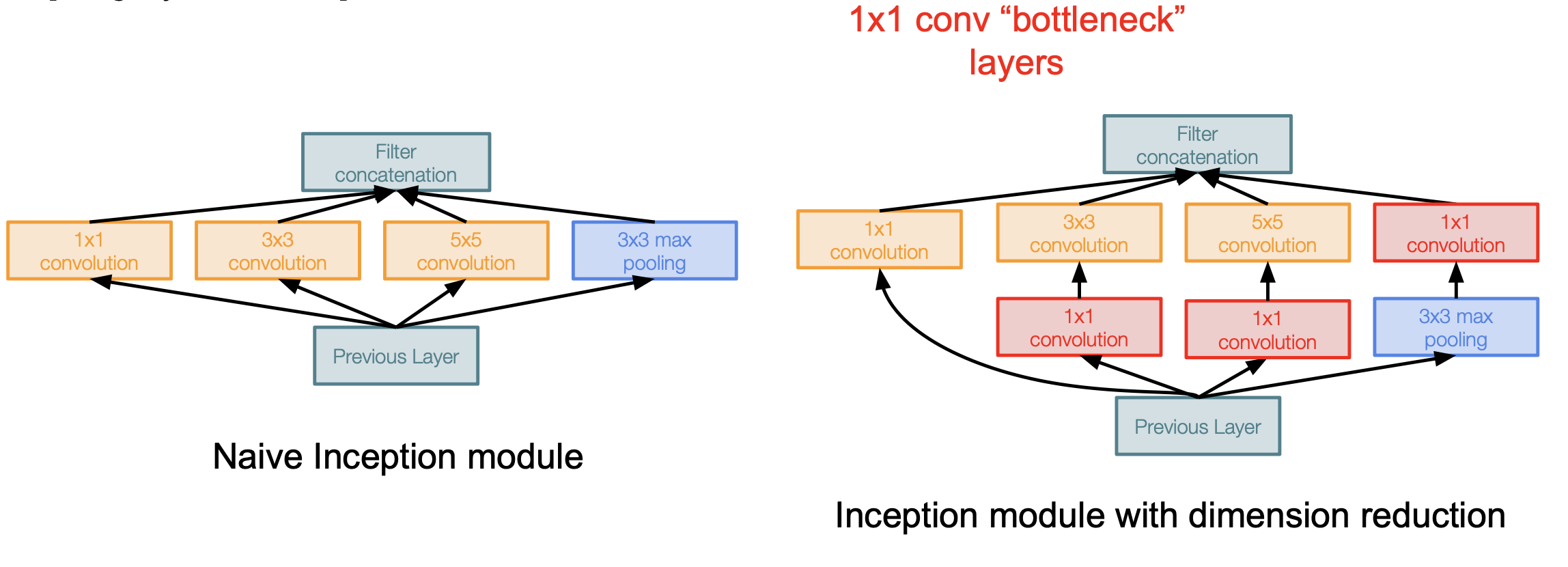
위 그림의 왼쪽이 단순한 모양의 Inception 모듈이고 오른쪽이 Bottlenect layer를 이용해서 feature depth를 줄이는 Inception 모듈이다.
이때의 계산량을 전과 비교해보면 확연히 줄어드는 것을 볼 수 있다.
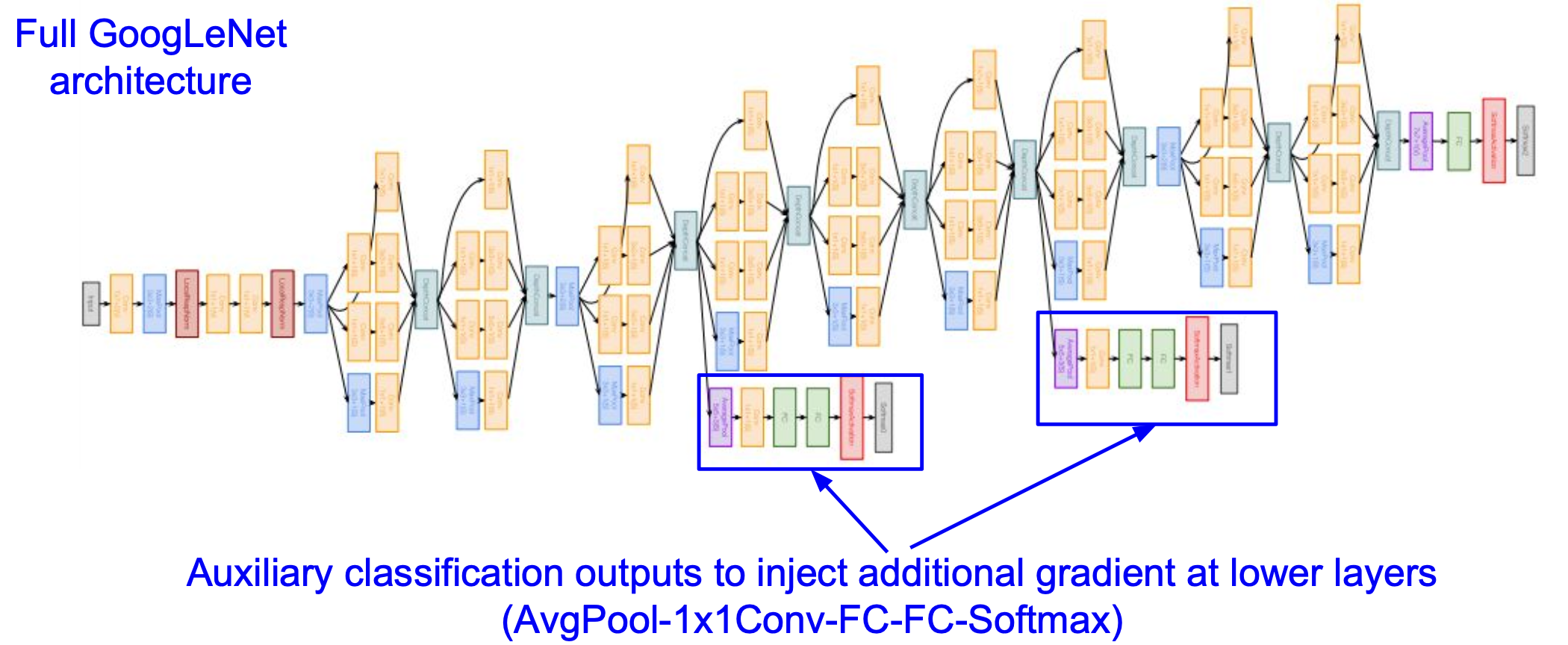
이런 GoogleNet의 전체 다이어그램을 보다 보면 이상한 부분이 보이는데 이 부분이 Auxiliary classification(보조 분류기)이다.
GoogleNet은 훈련 진행 중 보조 분류기에서도 loss를 계산하여 추가적인 gradient정보를 뒤쪽으로 흘려준다. 이는 네트워크가 깊어지면 깊어질수록 발생하는 gradient vanshing 문제를 완화하기 위함이다.
이 외에도 끝단에서 계산량이 많은 FC-layer들을 많이 걷어냄으로써 효율적인 계산을 할 수 있게 하고 파라미터 수도 줄였다.
ResNet
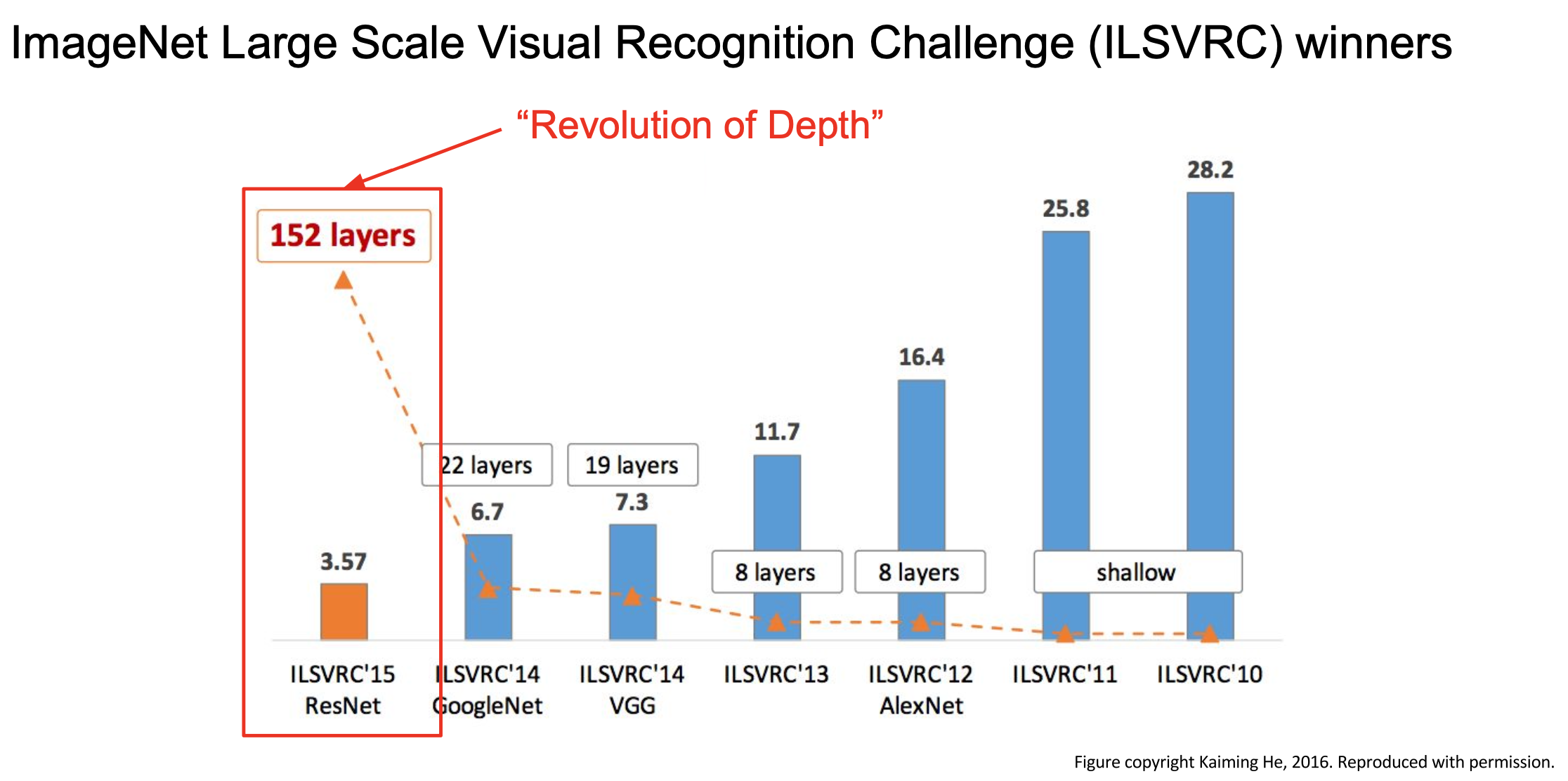
ResNet은 이전의 모델들과는 다르게 152개의 레이어라는 엄청나게 깊은 네트워크를 구성하면서도 성능을 향상했다. 이걸 가능하게 해 주는 것이 뒤에 나올 Residual connection이라는 것이다.
ResNet에 대한 설명을 하기에 앞서 왜 152개의 레이어를 쌓으면서 성능을 향상한 게 큰 일인지를 알아보자. 단순하게 생각하면 레이어를 많이 쌓으면 당연히 성능이 좋아지는 게 아닐까?라는 생각을 할 수 있지만 실제로는 그렇지 않다.
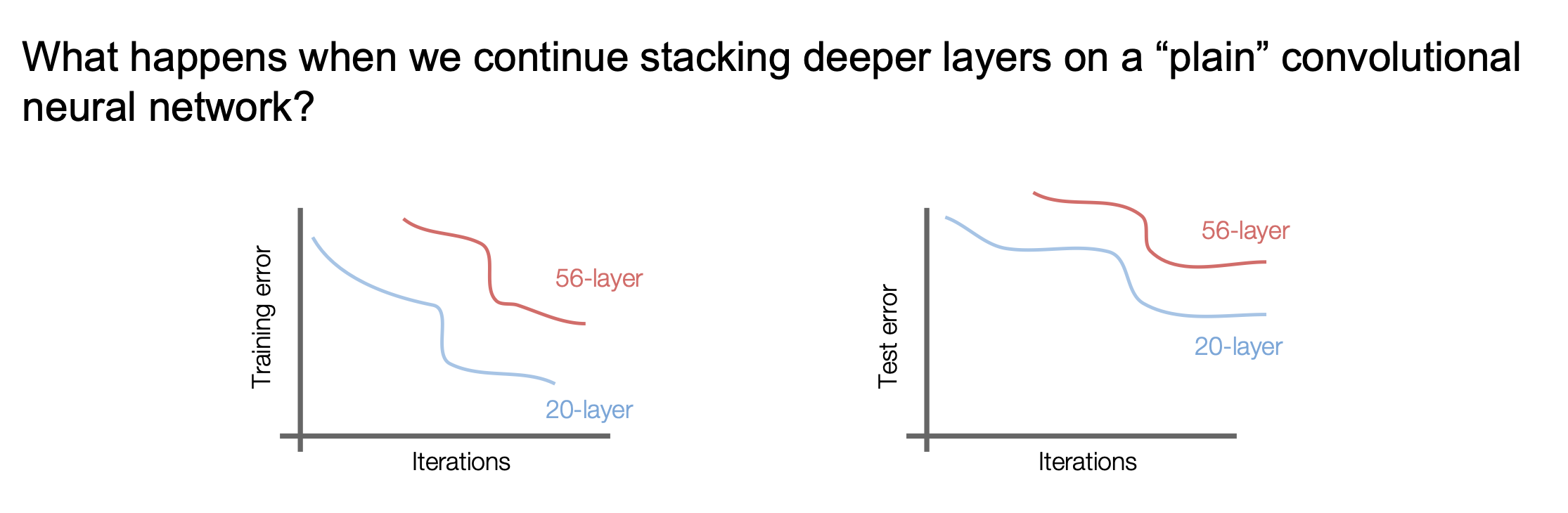
위 그림은 각각 20개의 레이어와 56개의 레이어를 가진 모델에 대해 Training error와 Test error를 시각화 한 자료이다. 예상과는 다르게 56개의 레이어를 가진 모델이 Test 과정에서 성능이 더 좋지 않다. 만약 레이어가 많아져서 과적합이 되었다면 Train 과정에서는 성능이 좋아야 하는데 왼쪽 그래프를 보면 그런 것도 아니다.
위 그래프를 보고 한 가설이 등장하는데, 바로 모델이 깊어질수록 최적화가 어렵다는 것이다.
이러한 문제를 해결하기 위해 나온 방법이 Residual connection이다.

더 깊은 네트워크를 만들기 위해 고민하던 사람들이 깊은 모델에서의 최적화 문제를 해결하기 위해 $H(x)$는 $x$에 어떤 $F(x)$를 더한 게 아닐까?라는 가설을 세우게 된다.
$H(x) = F(x) + x$
따라서 우리는 $H(x)$전부를 학습하는 게 아니라 $H(x)$와 $x$의 잔차(Residual)인 $F(x)$를 학습하자.라는 아이디어에서 만들어진 게 ResNet이다.
이 방법은 학습이 쉬워지는 장점이 있다. 만약 Input과 Output이 같아야 하는 상황이 있다면 단순히 $F(x)$를 0으로 만들어버리면 된다.
그리고 최적화를 위해 역전파를 할 때 미분을 계산하게 되는데 순전 파시에 입력 x가 identity mapping으로 그대로 들어가기 때문에 항상 1이 남게 되어 기울기 소실(gradient vanishing) 문제를 예방할 수 있다.
$H^\prime(x) = F^\prime(x) + 1$

이렇게 Residual block을 이용해 층을 깊게 쌓아주면 위 그림과 같은 모양이 된다.
모든 Resicual block은 두 개의 3X3 conv layer를 이용하였고, 일정 주기마다 stride=2를 이용해 downsampling을 해주게 된다.
그리고 마지막 부분에 FC-layer를 사용하지 않고 Global Average Pooling Layer를 사용해주고 마지막 output classes에 해당하는 FC 1000 레이어만 있다.

ResNet에서도 GoogleNet과 비슷하게 더 깊은 네트워크를 만들기 위해 Bottleneck layer를 사용한다.
실제 ResNet의 훈련과정은 다음과 같다.
- Conv layer를 거칠 때마다 Batch Normalization을 진행
- Xavier/2 initialization을 이용( 추가적인 Scailing factor 2가 추가됨)
- SGD+Momentum(0.9)
- LR = 0.1로 주고 val error가 평평해지는 구간에서 10씩 나눠주면서 진행
- Mini-batch size 256
- Weight decay of 1e-5
- No dropout

위 그림으로 모델별 정확도, 계산량, 메모리 사용량 등을 비교해볼 수 있다.
다음으로는 역사적으로 의미가 있거나 이후로 나온 모델들에 대한 간단한 설명이다.
Network in Network(NiN)

- 각 Conv layer안에 MLP를 쌓음(FC-layer를 몇 개 쌓는 격) → 초반 레이어에서 abstact feature를 잘 뽑도록 함
- 단순 Conv filter만 사용하는 게 아니라 좀 더 복잡한 계층으로 activation map을 얻어보자는 아이디어로 설계
- GoogleNet, RestNet보다 먼저 BottleNet 개념을 정립
Identity Mappings in Deep Residual Networks
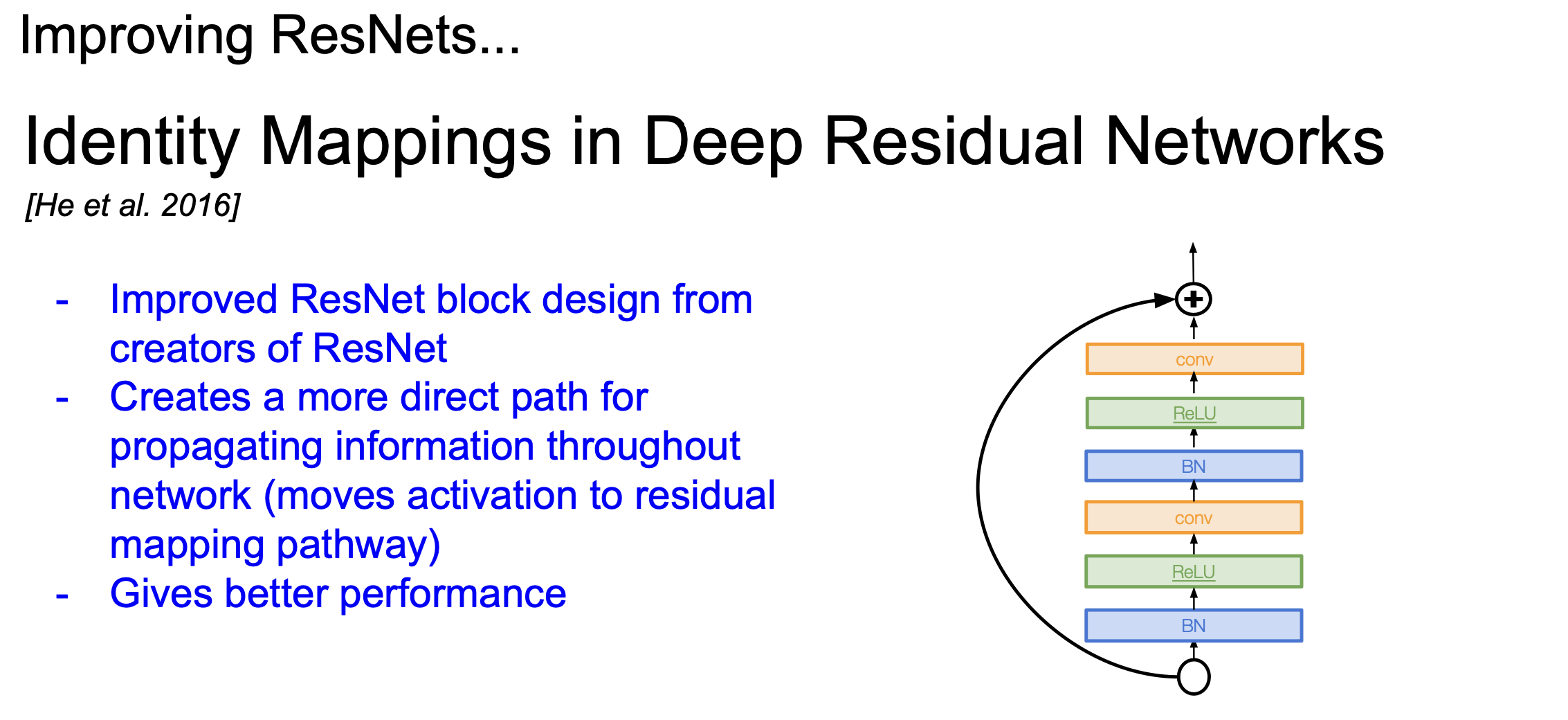
- ResNet을 디자인한 사람이 ResNet을 향상한 모양
- Residual block안에 층을 좀 더 많이 쌓음
Wide Residual Networks
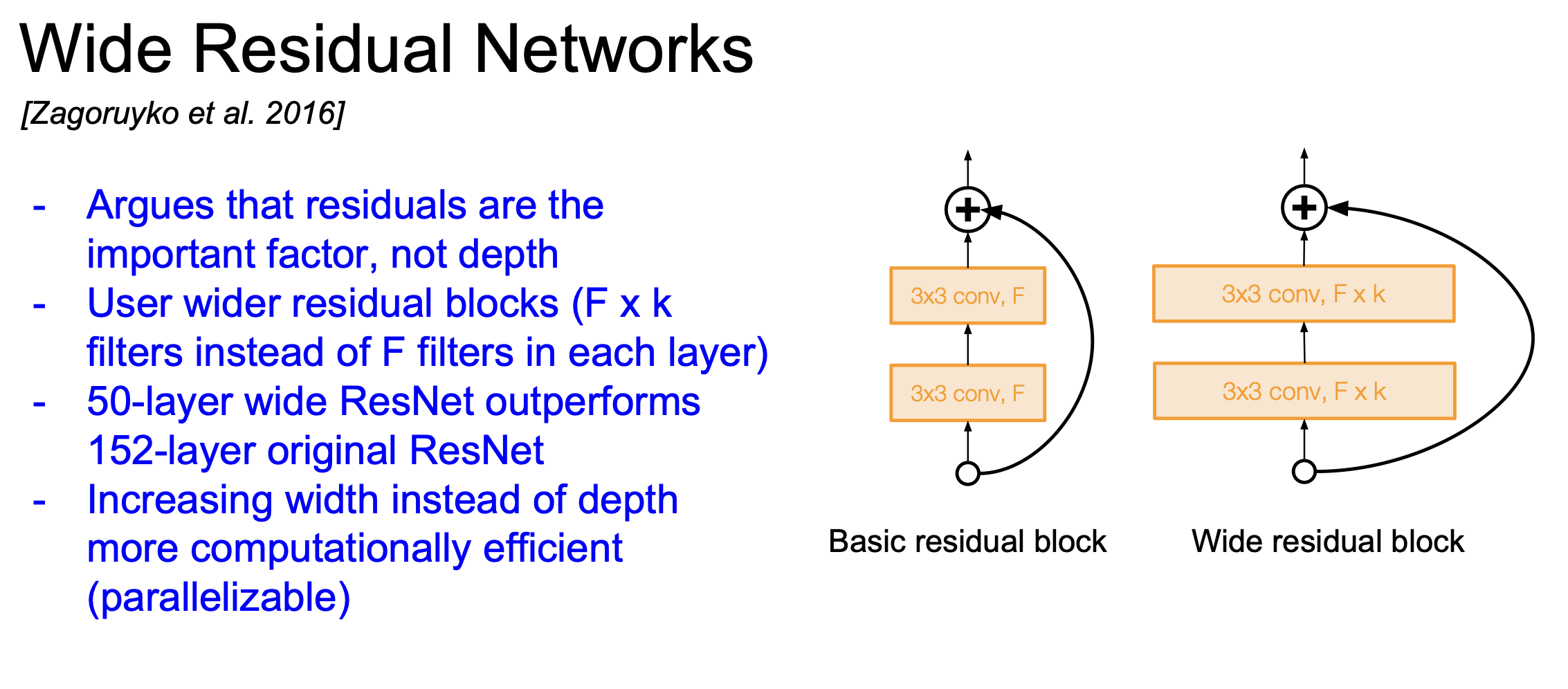
- Residual이 있으면 굳이 레이어가 많을 필요가 없다는 주장에 의해 디자인된 모델
- 네트워크의 깊이를 늘리는 게 아니라 residual block에서의 필터 개수를 늘림
- 필터의 개수를 늘리는 건 병렬 관계이기 때문에 계산 효율이 증가함
- 실제로 50개의 레이어를 이용해서 152개의 레이어를 가진 ResNet보다 성능이 좋아짐
ResNeXt
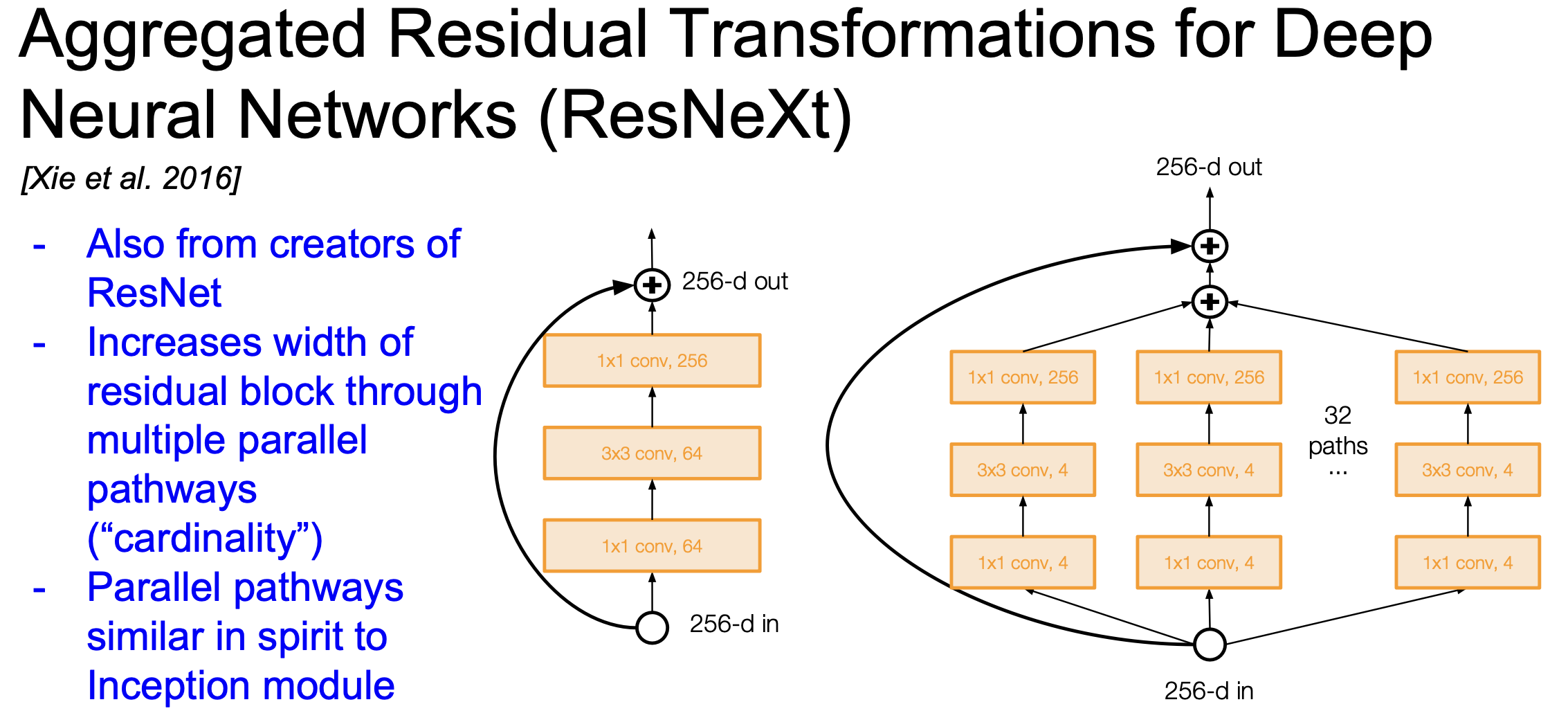
- Residual block안에 다중 병렬 경로를 추가함
- pathway의 총합을 cardinality라 부름
- 병렬화를 했다는 부분에서 ResNeXt와 Wide ResNet은 비슷 & Layer를 병렬로 묶었다는 것에서 Inception의 개념도 가져옴
Deep Networks with Stochastic Depth

- 경사 소실(gradient vanishing)을 줄이기 위해 훈련은 짧은 네트워크로 진행하자는 아이디어로 디자인됨
- 훈련 시에 레이어를 랜덤으로 꺼버림 → dropout과 유사 → Ensemble 효과를 얻을 수 있음
- 테스트 시에는 모든 레이어를 사용
지금까지는 ResNet의 변형이나 향상된 버전의 모델
아래는 Beyond ResNet을 지향하는 모델들
FractalNet : Ultra-Deep Neural Networks without Residuals

Residual이 굳이 필요 없다는 아이디어로 디자인된 모델
Densely Connected Convolutional Networks

각 레이어의 출력이 다른 레이어에서 여러 번 사용될 수 있기 때문에 gradient vanishing문제를 줄임
SqueezeNet

극한의 계산 효율로 디자인된 모델
이번 강의 내용은 과거부터 지금까지의 CNN Architectures의 아이디어와 작동 원리를 알아보는 내용이었습니다.
모델들을 제대로 이해하려면 논문을 봐야 하는데 강의에서 논문의 모든 내용을 설명할 수는 없으니 좀 간단하게(?) 설명하는 부분이 있어서 내용에 부족한 부분이 많습니다 ㅜ.ㅜ
추후에 관련 논문을 보게 된다면 각 모델에 대해 더 자세한 내용을 포스팅할 수 있도록 하겠습니다!
'AI > CS231N' 카테고리의 다른 글
| Lecture 10 : Recurrent Neural Networks (1) | 2022.09.06 |
|---|---|
| Lecture 11 : Detection and Segmentation (0) | 2022.09.03 |

