- 단어 빈도를 이용한 벡터화
(1) Bag of Words
(2) Bag of Words 구현해보기
(3) DTM과 코사인 유사도
(4) DTM의 구현과 한계점
(5) TF-IDF
(6) TF-IDF 구현하기 - LSA와 LDA
(1) LSA
(2) LSA 실습
(3) LDA
(4) LDA 실습 - 텍스트 분포를 이용한 비지도 학습 토크나이저
(1) 형태소 분석기와 단어 미등록 문제
(2) soynlp
1. 단어 빈도를 이용한 벡터화
(1) Bag of Words
자연어 처리에서 전처리 과정에 텍스트를 벡터로 변환하는 벡터화(Vetorization)라는 과정이 있습니다.
벡터화 방법으로는 크게 통계와 머신 러닝을 활용한 방법, 그리고 인공 신경망을 활용하는 방법으로 나눠볼 수 있습니다.
그중에서 Bag of Words는 단어의 순서는 고려하지 않고, 출현 빈도(frequency)만 고려하는 벡터화 방법입니다.

Bag of Words는 문서를 단어들의 가방이라고 가정합니다. 문서에 나오는 텍스트를 전부 단어 단위로 토큰화를 해주고 이 단어들을 전부 가방에 집어넣어 줍니다. 이때 가방 안에서 순서는 고려되지 않습니다.
그리고 가방 안에 단어들이 몇 개가 있는지 등장 횟수를 count 해줍니다.
단순하게 문서에서 단어들의 순서는 무시하고, 단어들의 빈도 정보만을 가지는 벡터를 만들어주는 방법입니다.
예를 들어 다음과 같은 문장이 2개 있다고 가정하겠습니다.
- hello world. he is myeong.
- my name is myeong.
이 두 개의 문장으로 Bag of Words를 만들면 다음과 같이 만들어질 것입니다.
BoW = {hello : 1, world : 1, he : 1, is : 2, myeong : 2, my : 1, name : 1}
(2) Bag of Words 구현
이번엔 텐서플로우 케라스와 사이킷런 라이브러리를 이용해 Bag of Words를 만들어 보겠습니다.
1. Keras Tokenizer 사용
from tensorflow.keras.preprocessing.text import Tokenizer
sentence = ['Hello world. He is myeong. my name is myeong']
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentence)
bow = dict(tokenizer.word_counts)
print('Bag of words : ', bow)
print('단어장의 크기 : ', len(tokenizer.word_counts))여기서 단어장이란 중복을 제거한 단어들의 집합을 말합니다. 이는 Bag of Words랑은 다른 개념입니다. 횟수는 상관없이 총 가방에 들어있는 서로 다른 단어의 종류(?)가 몇 개인지를 의미합니다.
2. scikit-learn CounterVectorizer 사용
from sklearn.feature_extraction.text import CountVectorizer
sentence = ['Hello world. He is myeong. my name is myeong']
vector = CountVectorizer()
bow = vector.fit_transform(sentence).toarray()
print('Bag of words : ', bow) # 문장으로부터 각 단어의 빈도수를 기록
print('단어장의 크기 : ', vector.vocabulary_) # 각 단어의 인덱스가 어떻게 부여되었는지를 보여줌케라스를 이용한 결과와 조금을 다릅니다. CounterVectorizer로 출력되는 bow 결과를 보면 각 단어의 빈도만 출력되고 어떤 단어의 빈도인지는 나오지 않습니다.
어떤 단어의 빈도인지 확인하려면 vector.vocabulary_ 를 통해서 각 단어에 부여된 인덱스를 확인하면 됩니다.
그리고 이 bow의 단어장을 크기는 아래와 같이 구하면 됩니다.
print('단어장의 크기 : ', len(vector.vocabulary_))
# output
단어장의 크기 : 7(3) DTM과 코사인 유사도
DTM(Document-Term Matrix)는 직역하면 문서-단어 행렬입니다. DTM은 여러 문서의 Bag of Words를 하나의 행렬로 구현한 것입니다. DTM은 문서를 행으로, 단어를 열로 가지는 행렬이지만, 문헌에 따라서는 열을 문서로, 행을 단어로 하는 TDM(Term-Document Matrix)라고 부르기도 합니다.
예를 들어, 아래와 같은 4개의 문서가 있다고 하겠습니다.
문서 1 : 먹고 싶은 사과
문서 2 : 먹고 싶은 바나나
문서 3 : 길고 노란 바나나 바나나
문서 4 : 저는 과일이 좋아요
위 문서들을 공백 기준으로 토큰화한다고 가정하고, DTM을 만들어보면 아래와 같습니다.
| 먹고 | 싶은 | 사과 | 바나나 | 길고 | 노란 | 저는 | 과일이 | 좋아요 | |
| 문서 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 문서 2 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 문서 3 | 0 | 0 | 0 | 2 | 1 | 1 | 0 | 0 | 0 |
| 문서 4 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
위의 DTM을 보면 각 행은 문서, 각 열은 문서 4개의 통합 단어장에 있는 단어들로 구성되어 있는 것을 알 수 있습니다.
이때 각 행을 문서 벡터(document vector), 열을 단어 벡터(word vector)라고 부를 수 있습니다. 문서의 수가 많아지면 많아질수록, 단어장의 크기도 커지게 되어서 DTM은 결국 대부분의 값이 0이 되는 희소 행렬의 형태를 띠게 됩니다.
이제 각 문서 벡터의 유사도를 구해보겠습니다. 가장 보편적으로 사용되는 코사인 유사도를 이용하겠습니다.
먼저 문서 벡터와 코사인 유사도 함수를 정의하겠습니다.
import numpy as np
from numpy import dot
from numpy.linalg import norm
doc1 = np.array([1,1,1,0,0,0,0,0,0]) # 문서1 벡터
doc2 = np.array([1,1,0,1,0,0,0,0,0]) # 문서2 벡터
doc3 = np.array([0,0,0,2,1,1,0,0,0]) # 문서3 벡터
doc4 = np.array([0,0,0,0,0,0,1,1,1]) # 문서4 벡터
def cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))여기서 코사인 유사도란 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미합니다. 이를 직관적으로 이해하면 두 벡터가 가리키는 방향이 얼마나 유사한가를 의미합니다.
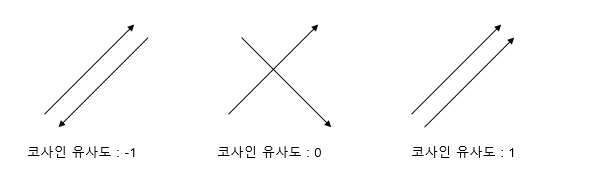
두 벡터 A, B에 대해 코사인 유사도는 식으로 표현하면 다음과 같습니다.
similarity=cos(θ)=A⋅B∥A∥∥B∥=∑ni=1Ai×Bi√∑ni=1(Ai)2×√∑ni=1(Bi)2
이렇게 계산된 유사도는 1에 가까울수록 유사도가 높다고 판단한 수 있습니다.
각 문서에 대해서 코사인 유사도를 계산해 보겠습니다.
print(cos_sim(doc1, doc2)) #문서1과 문서2의 코사인 유사도
print(cos_sim(doc1, doc3)) #문서1과 문서3의 코사인 유사도
print(cos_sim(doc2, doc3)) #문서2과 문서3의 코사인 유사도
print(cos_sim(doc3, doc4)) #문서3과 문서4의 코사인 유사도
(4) DTM의 구현과 한계점
- scikit-learn CountVectorizer 이용
사이킷런의 CountVectorizer를 이용하여 DTM을 만드는 방법은 앞서 Bag of Words를 만드는 방법과 동일합니다. 한 가지 차이점은 다수의 문장을 입력으로 준다는 것입니다.
from sklearn.feature_extraction.text import CountVectorizer
sentence = ['먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요']
vector = CountVectorizer()
print(vector.fit_transform(sentence).toarray())
print(vector.vocabulary_)
- DTM의 한계점
- 희소 표현 : 문서의 수와 단어의 수가 계속 늘어날수록, 행과 열은 대부분의 값으로 0을 가집니다. 이는 많은 양의 저장 공간과 높은 계산 복잡도를 요구합니다.
- 단어의 빈도에만 집중하는 방법 자체의 문제 : 예를 들어 한국인들의 대화 데이터를 가지고 DTM을 만들었을 때 '아니'라는 단어는 어떤 문장에서도 자주 등장할 것입니다. 그럼 '아니'라는 단어가 등장한다고 유사한 문서라고 봐도 되는지에 대한 문제가 생기게 됩니다.
(5) TF-IDF
TF-IDF란 각 단어의 중요도를 판단하여 가중치를 주는 방법입니다.
TF-IDF는 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단하며, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단하는 것입니다.
TF-IDF는 Term Frequency-Inverse Document Frequency의 약자로 '단어 빈도-역문서 빈도'입니다.
하지만 TF-IDF를 사용하는 것이 반드시 DTM을 사용하는 것보다 성능이 뛰어난 것은 아닙니다.
그럼 먼저 TF-IDF의 수식을 보겠습니다.
Wx,y=tf(x,y)×log(N1+df(x))
- tf(x,y) : frequency of x in y
- df(x) : number of documents containing x
- N : total number of documents
위 식은 y는 문서, x는 단어라고 할 때의 TF-IDF의 수식입니다. TF는 각 문서에 등장하는 단어의 빈도를 의미하므로 DTM을 만들면 자연스럽게 해결됩니다.
DF는 단어 x를 포함하는 문서의 수입니다. 그리고 분모에 1+df(x)를 해준 것은 분모가 0이 되는 것을 방지하기 위함입니다.
(6) TF-IDF 구현하기
이제 TF-IDF를 실제로 구현해보겠습니다.
우선 필요한 모듈을 임포트하고 사용할 문장을 정해주겠습니다.
from math import log
import pandas as pd
sentence = ['먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요']DTM의 열을 만들기 위해 문서 4개의 단어들이 모두 들어간 통합 단어장을 만들겠습니다.
vocab = []
for i in sentence:
token = i.split()
for j in token:
vocab.append(j)
vocab=list(set(vocab))
print('단어장의 크기 :', len(vocab))
print(vocab)
이제 TF 함수, IDF 함수, TF-IDF 함수를 만들겠습니다.
N = len(sentence)
def tf(t, d):
return d.count(t)
def idf(t):
df = 0
for sen in sentence:
if t in sen:
df += 1
return log(N / (1+df)) + 1 # 로그에 1을 더해주는 이유는 idf값이 0이 되는것을 방지하기 위함입니다.
def tfidf(t, d):
return tf(t, d) * idf(t)DTM 행렬을 만들어 보겠습니다.
result = []
for i in range(N):
dtm_row = []
d = sentence[i]
for j in range(len(vocab)):
t = vocab[j]
dtm_row.append(tf(t, d))
result.append(dtm_row)
dtm = pd.DataFrame(result, columns = vocab)
dtm
각 단어의 IDF를 구해보겠습니다.
idf_result = []
for t in vocab:
idf_result.append(idf(t))
idf = pd.DataFrame(idf_result, index=vocab, columns = ['IDF'])
idf
이제 TF-IDF 행렬을 출력해보겠습니다.
DTM에 있는 각 단어의 TF에 각 단어의 IDF를 곱해준 값입니다.
result_tfidf = []
for i in range(N):
tfidf_row = []
d = sentence[i]
for j in range(len(vocab)):
t = vocab[j]
tfidf_row.append(tfidf(t, d))
result_tfidf.append(tfidf_row)
tfidf_df = pd.DataFrame(result_tfidf, columns = vocab)
tfidf_df
- scikit-learn TFidfVectorizer 이용
사이킷런으로 DTM을 만들기 위해서는 CountVectorizer를 사용했습니다. 이와 유사하게 TF-IDF를 자동으로 계산하여 출력하는 TfidfVectorizer가 사이킷런에 있습니다.
사실 사이킷런의 TfidfVectorizer의 동작은 우리가 만든 식과는 차이가 있습니다. log항의 분자에도 1을 더해주고 TF-IDF의 결과에 L2 Norm을 추가로 수행합니다.
사이킷런의 TfidfVectorizer를 통해 TF-IDF 행렬을 출력해보겠습니다.
from sklearn.feature_extraction.text import TfidfVectorizer
sentence = ['먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요']
tfidf_vector = TfidfVectorizer().fit(sentence)
vocab = list(tfidf_vector.vocabulary_.keys())
vocab.sort()
tfidf_ = pd.DataFrame(tfidf_vector.transform(sentence).toarray(), columns = vocab)
tfidf_
2. LSA와 LDA
(1) LSA
DTM와 TF-IDF 행렬같이 Bag of Words를 기반으로 한 표현 방법은 근본적으로 단어의 의미를 벡터로 표현하지 못한다는 문제가 있습니다. 단어들의 빈도가 아닌 의미와 주제를 알아내기 위한 방법으로 LSA(Latent Semantic Analysis)가 있습니다.
- LSA(Latent Semantic Analysis)
잠재 의미 분석이라는 의미를 가진 LSA는 전체 corpus에서 문서 속 단어 사이의 관계를 찾아내는 자연어 처리 정보 검색 기술입니다.
LSA를 사용하면 단어와 단어 사이, 문서와 문서 사이, 단어와 문서 사이의 의미적 유사성 점수를 찾아낼 수 있습니다.
- 특이값 분해
LSA를 이해하기 위해선 먼저 선형대수학의 특잇값 분해(Singular Value Decomposition)에 대해 이해할 필요가 있습니다.

특이값 분해(Singular Value Decomposition, SVD)란 m×n 크기의 임의의 사각 행렬 A를 위 그림의 Full SVD같이 3개의 행렬로 나누는 것을 말합니다.
그리고 이런 특이값 분해 중에서 Truncated SVD라는 것이 있습니다. 특이값 중에 가장 중요한 t개의 특잇값만 남기고 거기 해당되는 특이벡터들고 행렬 A를 근사하는 방법입니다. 어떻게 보면 차원을 낮춘다(?)라고 볼 수 있는 것 같습니다.

A=USVT
LSA는 DTM이나 TF-IDF 행렬에 Truncated SVD를 수행합니다.
이렇게 분해하여 얻은 행렬 3개(Uk,VTk,S)는 각각
- Uk : 문서들과 관련된 의미들을 표현한 행렬
- VTk : 단어들과 관련된 의미를 표현한 행렬
- S : 각 의미의 중요도를 표현한 행렬
이라고 해석할 수 있습니다.
우리는 특잇값 중 가장 중요한(가장 큰) 순서로 k개만 남기고 그에 해당하는 특이 벡터들만 사용합니다.
이때의 VTk행렬의 k열은 전체 corpus로부터 얻어낸 k개의 주제라고 간주할 수도 있습니다.
(2) LSA 실습
파이썬으로 한 번 실습을 해보겠습니다.
import numpy as np
import pandas as pd
import urllib.request
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
# 다운로드 해줘야 nltk가 제대로 작동합니다.
nltk.download('punkt')
nltk.download('wordnet')
nltk.download('stopwords')실습을 위한 데이터를 다운로드해주고 5개의 샘플을 확인해보겠습니다.
# 데이터 다운로드에 대한 부분은 굳이 작성하지 않겠습니다.
data.head()
publish_data는 필요가 없으니까 headline_text만 별도로 저장한 후 중복치가 있다면 제거해주겠습니다.
# headline_text 부분만 가져옴
text = data[['headline_text']].copy()
text.drop_duplicates(inplace=True) # 중복 샘플 제거
text.reset_index(drop=True, inplace=True)
text.shape
# output
(1054983, 1)중복 데이터도 제거했으니 NLTK의 토크나이저를 이용해 전체 텍스트 데이터에 대해 단어 토큰화를 수행하고, 불용어를 제거하겠습니다.
test['headline_text'] = text.apply(lambda row : nltk.word_tokenize(row['headline_text']), axis=1)
stop_words = stopwords.words('english')
text['headline_text'] = text['headline_text'].apply(lambda x : [word for word in x if word not in stop_words])
text.head()
이번에는 표제어 추출(Lemmatization), 길이가 1~2인 단어를 제거하겠습니다.
# 다운로드를 진행해야 표제어 추출이 가능합니다.
nltk.download('omw-1.4')
# 단어 정규화
text['headline_text'] = text['headline_text'].apply(lambda x : [WordNetLemmatizer().lemmatize(word, pos='v') for word in x])
# 길이가 1~2인 단어 제거
text['headline_text'] = text['headline_text'].apply(lambda x : [word for word in x if len(word) > 2])
print(text[:5])
정제된 데이터를 이용해 DTM을 생성하는 CountVectorizer 또는 TF-IDF 행렬을 생성하는 TfidfVectorizer를 실행하기 위해 토큰화 된 문장을 다시 합쳐줍니다.
# 역토큰화 : 토큰화 작업을 역으로 수행
detokenized_doc = []
for i in text:
t = ' '.join(i)
detokenized_doc.append(t)
train_data = detokenized_doc
train_data[:5]
CountVectorizer를 이용해 DTM을 생성해보겠습니다. 단어의 수는 5,000개로 제한해주겠습니다.
# 상위 5000개의 단어만 사용
c_vectorizer = CountVectorizer(stop_words='english', max_features = 5000)
document_term_matrix = c_vectorizer.fit_transform(train_data)
print('행렬의 크기 : ', document_term_matrix.shape)
# output
(1054983, 5000)이제 사이킷런의 TruncatedSVD를 이용해 LSA를 수행해보겠습니다. 토픽의 수는 10으로 정하겠습니다.
from sklearn.decomposition import TruncatedSVD
n_topics = 10
lsa_model = TruncatedSVD(n_components = n_topics)
lsa_model.fit_transform(document_term_matrix)
TruncatedSVD를 통해 얻은 VTk의 크기를 확인해보면 k×(단어의수)의 크기를 가지는 것을 확인할 수 있습니다.
이제 행렬의 각 행을 전체 corpus의 주제로 판단하고 각 주제에서 n개씩의 단어를 출력해보겠습니다.
terms = c_vectorizer.get_feature_names() # 단어 집합. 5,000개의 단어가 저장됨.
def get_topics(components, feature_names, n=5):
for idx, topic in enumerate(components):
print("Topic %d:" % (idx+1), [(feature_names[i], topic[i].round(5)) for i in topic.argsort()[:-n - 1:-1]])
get_topics(lsa_model.components_, terms)
(3) LDA
앞에서 진행했던 LSA처럼 문서의 집합에서 토픽을 찾아내는 프로세스를 토픽 모델링(Topic Modelling)이라고 합니다. 이번에 배울 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)은 토픽 모델링의 또 다른 알고리즘입니다. LDA에서는 문서들이 토픽들의 혼합으로 구성되어 있으며, 토픽들은 확률 분포에 기반하여 단어를 생성한다고 가정합니다. 이러한 가정에 따라 단어의 분포로부터 문서가 생성되는 과정을 역추적해 토픽을 찾아내게 됩니다.
LDA는 DTM 또는 TF-IDF 행렬을 입력으로 합니다. 이를 통해 우리는 LDA가 단어의 순서는 신경 쓰지 않는 것을 알 수 있습니다.
자세한 설명을 여기로 가시면 볼 수 있습니다.
간단하게 요약하자면 다음과 같습니다.
- LSA : DTM을 차원 축소하여 축소 차원에서 근접 단어들을 토픽으로 묶는다.
- LDA : 단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합 확률로 추정하여 토픽을 추출한다.
LDA에 대한 동영상 강의가 있어 이 강의를 통해 이해하는 것도 좋을 것 같습니다.
(4) LDA 실습
실습에 사용할 데이터는 아까 만들어둔 train_data를 재사용하겠습니다.
방금 LDA는 DTM 또는 TF-IDF 행렬을 입력으로 받는다고 했습니다.
여기서는 TF-IDF를 입력으로 사용하겠습니다.
# 상위 5,000개의 단어만 사용
tfidf_vectorizer = TfidfVectorizer(stop_words='english', max_features=5000)
tf_idf_matrix = tfidf_vectorizer.fit_transform(train_data)
# TF-IDF 행렬의 크기를 확인해봅시다.
print('행렬의 크기 :', tf_idf_matrix.shape)
# output
(1054983, 5000)사이킷런의 LDA를 사용해서 학습해보겠습니다.
from sklearn.decomposition import LatentDirichletAllocation
lda_model = LatentDirichletAllocation(n_components=10, learning_method='online', random_state=777, max_iter=1)
lda_model.fit_transform(tf_idf_matrix)
각 토픽에서의 단어의 비중을 보겠습니다.
terms = tfidf_vectorizer.get_feature_names_out() # 단어 집합. 5,000개의 단어가 저장됨.
def get_topics(components, feature_names, n=5):
for idx, topic in enumerate(components):
print("Topic %d:" % (idx+1), [(feature_names[i], topic[i].round(5)) for i in topic.argsort()[:-n - 1:-1]])
get_topics(lda_model.components_, terms)
3. 텍스트 분포를 이용한 비지도 학습 토크나이저
(1) 형태소 분석기와 단어 미등록 문제
우리가 한국어 토큰화를 진행할 때 한국어는 교착어라 영어와 다르게 띄어쓰기 단위 토큰화가 어렵습니다.
띄어쓰기를 기준으로 토큰화를 하면 어떤 문제가 생기는지 한 번 확인해보겠습니다.
kor_text = "사과의 놀라운 효능이라는 글을 봤어. 그래서 오늘 사과를 먹으려고 했는데 사과가 썩어서 슈퍼에 가서 사과랑 오렌지 사 왔어"
print(kor_text.split())
# output
['사과의', '놀라운', '효능이라는', '글을', '봤어.', '그래서', '오늘', '사과를', '먹으려고', '했는데', '사과가', '썩어서', '슈퍼에', '가서', '사과랑', '오렌지', '사', '왔어']한눈에 봐도 '사과의', '사과를', '사과가' 이 3 단어는 결국 '사과'라는 단어를 의미합니다. 하지만 '의', '를', '가'가 붙어서 컴퓨터는 전부 다른 단어로 인식할 수 있습니다. 이를 위해 한국어 형태소 분석기가 있는데 KoNLPy에서 제공하는 Okt를 이용해서 한 번 형태소 기반 토큰화를 해보겠습니다.
from konlpy.tag import Okt
tokenizer = Okt()
print(tokenizer.morphs(kor_text))|
['사과', '의', '놀라운', '효능', '이라는', '글', '을', '봤어', '.', '그래서', '오늘', '사과', '를', '먹으려고', '했는데', '사과', '가', '썩어서', '슈퍼', '에', '가서', '사과', '랑', '오렌지', '사', '왔어']
|
하지만 이런 분석기는 등록된 단어를 기준으로 형태소를 분류하기 때문에 새롭게 만들어진 단어를 인식하기 어렵다는 단점이 있습니다.
(2) soynlp
soynlp는 품사 태깅, 형태소 분석 등을 지원하는 한국어 형태소 분석기입니다.
비지도 학습을 기반으로 한 접근법을 이용해 통계적 패턴을 이용하여 단어를 추출한다고 합니다.
내부적으로 cohension probability와 branching entropy를 단어 점수로 사용합니다.
사용을 위해 soynlp 깃허브에서 제공하는 말뭉치를 다운로드해주고 문서 단위로 분리해주겠습니다.
from soynlp import DoublespaceLineCorpus
# 말뭉치에 대해서 다수의 문서로 분리
corpus = DoublespaceLineCorpus(txt_filename)문서를 한 번 뽑아 보겠습니다.
i = 0
for document in corpus:
if len(document) > 0:
print(document)
i = i+1
if i == 3:
break
sonlpy를 말뭉치에 대해서 학습을 진행해주겠습니다.
from soynlp.word import WordExtractor
word_extractor = WordExtractor()
word_extractor.train(corpus)
word_score_table = word_extractor.extract()
앞서 cohesion probability(응집 확률)을 사용한다고 했습니다. 응집 확률이란 내부 문자열이 얼마나 응집하여 등장하는지를 판단하는 척도입니다.
수식은 아래와 같습니다.
cohesion(n)=(n−1∏i=1P(c1:i+1|c1:i))1n−1
그리고 branching entropy(브랜칭 엔트로피)도 사용한다고 했는데요. 브랜칭 엔트로피는 확률 분포의 엔트로피 값을 사용합니다. 이는 주어진 문자열에서 얼마나 다음 문자가 등장할 수 있는지를 판단하는 척도입니다.
자세한 내용은 아래 사이트에서 볼 수 있습니다.
10) 한국어 전처리 패키지(Text Preprocessing Tools for Korean Text)
유용한 한국어 전처리 패키지를 정리해봅시다. 앞서 소개한 형태소와 문장 토크나이징 도구들인 KoNLPy와 KSS(Korean Sentence Splitter)와 함께 유용하 ...
wikidocs.net
이번에는 문서에 있는 단어들을 컴퓨터에서 인식하게 하기 위해 벡터로 바꾸는 방법에 대해서 알아보았습니다.
처음에는 단순히 빈도수만을 이용해 표현했고, 하지만 단어의 위치에 대한 정보가 사라져서 tf-idf라는 방법을 이용했습니다.
거기에 더해서 토픽을 뽑아낼 수 있는 LSA, LDA도 배웠습니다.
마지막으로 한국어 토큰화의 문제점 때문에 필요한 형태소 기반의 분석기와 형태소 분석기의 문제점을 해결하기 위해 만들어진 sonlpy에 대해서도 배웠습니다.
정리를 하고도 계속 찾아보면서 확실히 이해하고 활용까지 할 수 있도록 해봐야겠습니다.
1) 코사인 유사도(Cosine Similarity)
BoW에 기반한 단어 표현 방법인 DTM, TF-IDF, 또는 뒤에서 배우게 될 Word2Vec 등과 같이 단어를 수치화할 수 있는 방법을 이해했다면 이러한 표현 방법에 대 ...
wikidocs.net
4) TF-IDF(Term Frequency-Inverse Document Frequency)
이번에는 DTM 내에 있는 각 단어에 대한 중요도를 계산할 수 있는 TF-IDF 가중치에 대해서 알아보겠습니다. TF-IDF를 사용하면, 기존의 DTM을 사용하는 것보다 보 ...
wikidocs.net
1) 잠재 의미 분석(Latent Semantic Analysis, LSA)
LSA는 정확히는 토픽 모델링을 위해 최적화 된 알고리즘은 아니지만, 토픽 모델링이라는 분야에 아이디어를 제공한 알고리즘이라고 볼 수 있습니다. 이에 토픽 모델링 알고리즘인 ...
wikidocs.net
sklearn.decomposition.TruncatedSVD
Examples using sklearn.decomposition.TruncatedSVD: Hashing feature transformation using Totally Random Trees Hashing feature transformation using Totally Random Trees Manifold learning on handwritt...
scikit-learn.org
'AI > NLP Study' 카테고리의 다른 글
| [NLP] 임베딩 편향성 (0) | 2022.10.02 |
|---|---|
| [NLP] 워드 임베딩 (1) | 2022.10.01 |
| [NLP] 텍스트 카테고리 분류 (1) | 2022.09.29 |
| [NLP] 단어사전 만들기 (1) | 2022.09.25 |
| [NLP] 자연어 전처리 : 토큰화 (3) | 2022.09.21 |



