이 게시물은 밑바닥부터 시작하는 딥러닝 1권을 바탕으로 작성되었습니다.
계산 그래프
계산 그래프(computational graph)는 계산 과정을 그래프로 나타낸 것입니다. 계산 그래프는 복수의 노드(node)와 에지(edge)로 표현됩니다.
그럼 간단한 문제를 계산 그래프를 이용해 풀어보겠습니다.
- 문제 1 : 현빈 군은 슈퍼에서 1개에 100원인 사과를 2개 샀습니다. 이때 지불 금액을 구하세요. 단, 소비세가 10% 부과됩니다.
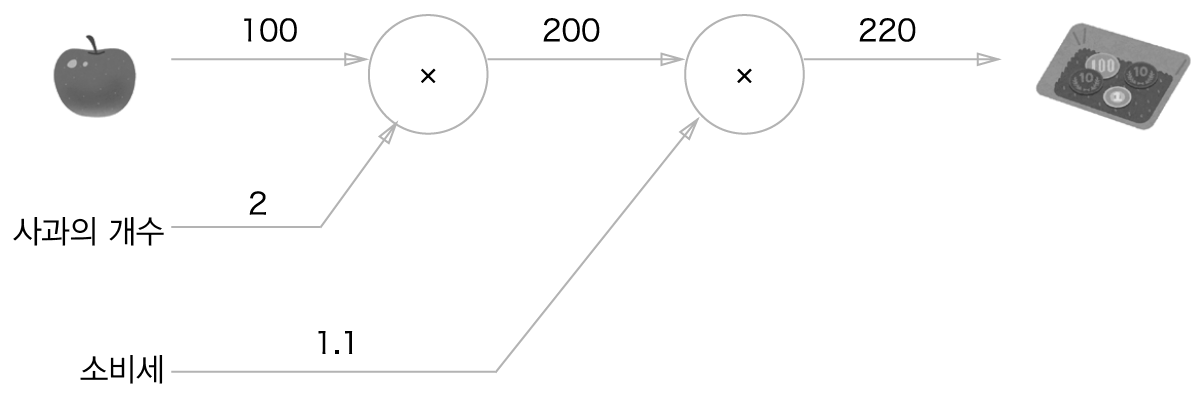
그림에서 처음에 곱셈 노드에 사과 1개의 가격과 사과의 개수가 입력으로 들어갑니다. 그에 대한 출력이 200으로 나오게 되고, 그 출력과 소비세 10%에 관한 값이 다음 곱셈 노드의 입력으로 들어가고 최종 지불 금액이 계산됩니다.
이처럼 계산 그래프를 그려서 왼쪽으로 오른쪽으로 진행하면서 계산하게 되는 순전파(forward propagation)이라고 합니다.
계산 그래프의 큰 특징으로는 '국소적 계산'을 전파함으로써 최종 결과를 얻는다는 점입니다. 국소적 계산이란 전체에서 어떤 일이 벌어지든 상관없이 자신과 관계된 정보만으로 결과를 출력할 수 있다는 것입니다.
위 그림에서는 각 노드에서의 계산이 국소적 계산에 해당합니다.
하지만 계산 그래프를 이용하는 가장 큰 이유는 역전파를 통해 '미분'을 효율적으로 계산할 수 있다는 점에 있습니다.

역전파를 할 때 위 그림과 같이 오른쪽에서 왼쪽으로 국소적 미분이 전달됩니다. 이 결과로부터 사과의 가격이 만약 1원이 오르게 된다면 최종 금액은 2.2원이 증가한다는 것을 알 수 있습니다. 이러한 특징을 이용해서 W가 아주 조금 변할 때 결괏값이 얼마나 변할지에 대한 것도 계산할 수 있을 것입니다.
연쇄 법칙
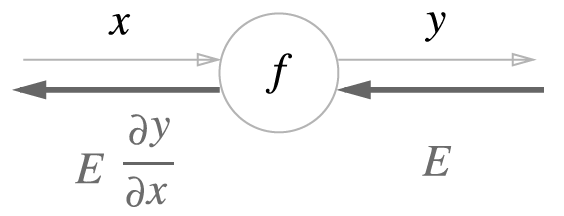
그림과 같이 역전파의 계산 절차는 신호 $E$에 노드의 국소적 미분 ($\frac{\partial y}{\partial x}$)을 곱한 후 다음 노드로 전달하는 것입니다. 여기에서 말하는 국소적 미분은 순전파 때의 $y = f(x)$ 계산의 미분을 구한다는 것이며, 이는 x에 대한 y의 미분 $\frac{\partial y}{\partial x}$를 구한다는 뜻입니다.
연쇄 법칙이란?
연쇄 법칙을 설명하려면 우선 합성 함수부터 알아야 합니다. 합성 함수란 여러 함수로 구성된 함수입니다. 예를 들어 $z = (x+y)^2$이라는 식은 아래 두 개의 식으로 구성됩니다.
$$z=t^2 \\
t = x + y$$
연쇄 법칙은 합성 함수의 미분에 대한 성질이며, 다음과 같이 정의됩니다.
합성 함수의 미분은 합성 함수를 구성하는 각 함수의 미분의 곱으로 나타낼 수 있다.
위 식에서 x에 대한 z의 미분($\frac{\partial z}{\partial x}$)을 나타내면 아래와 같이 표현됩니다.
$$\frac{\partial z}{\partial x} = \frac{\partial z}{\partial t} \frac{\partial t}{\partial x} = 2t \cdot 1 = 2(x+y)$$
위의 연쇄 법칙을 계산 그래프로 나타내 보겠습니다.

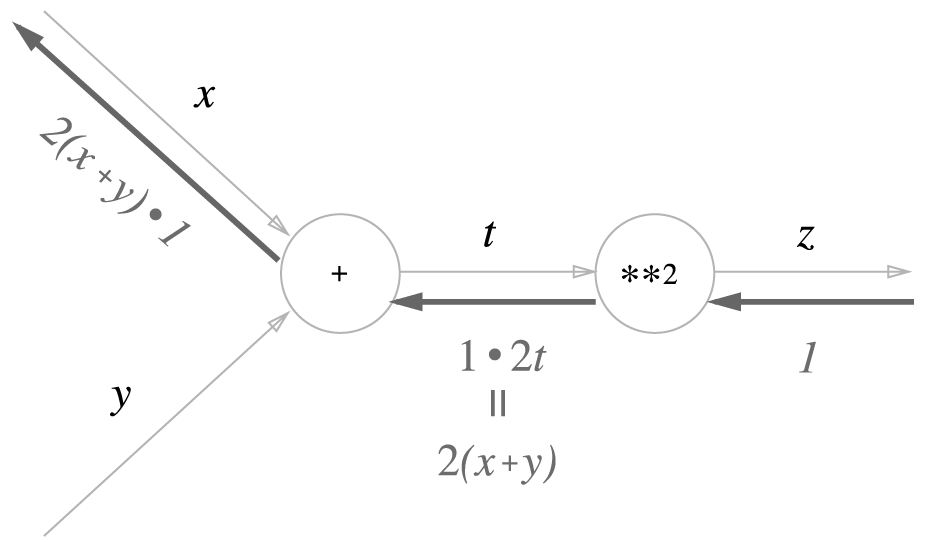
덧셈 노드의 역전파

곱셈 노드의 역전파
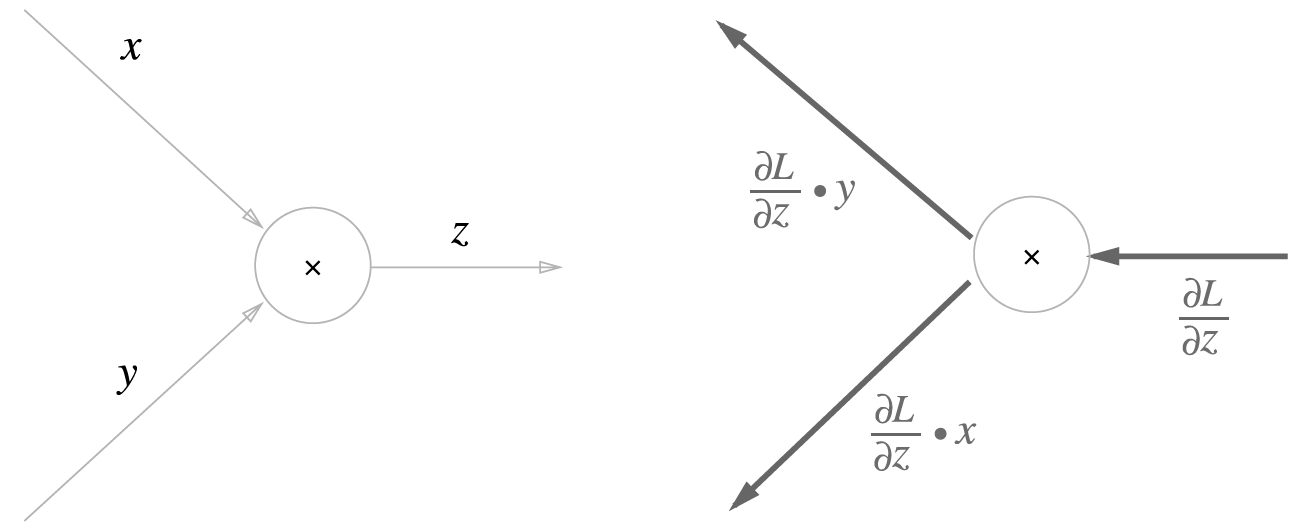
곱셈 노드의 역전 파는 덧셈 노드와 다르게 순전파의 입력 신호가 필요합니다. 따라서 곱셈 노드 구현시에는 순전파의 입력 신호를 변수에 저장해둡니다.
곱셈, 덧셈 계층의 구현
곱셈 노드와 덧셈 노드를 한 번 간단하게 구현해보겠습니다.
class MulLayer:
def __init__(self):
# 역전파에 사용할 x, y 변수
self.x = None
self.y = None
def forward(self, x, y):
self.x = x
self.y = y
out = x * y
return out
def backward(self, dout):
dx = dout * self.y # x와 y를 바꾼다.
dy = dout * self.x
return dx, dyclass AddLayer:
def __init__(self):
pass
def forward(self, x, y):
out = x + y
return out
def backward(self, dout):
dx = dout * 1
dy = dout * 1
return dx, dy활성화 함수 계층 구현하기
ReLU 계층
ReLU의 수식은 다음과 같습니다.
$$y =\begin{cases}x & x > 0\\0 & x \leq 0\end{cases}$$
위 식에서의 x에 대한 y의 미분은 다음과 같습니다.
$$\frac{\partial y}{\partial x} =\begin{cases}1 & x > 0\\0 & x \leq 0\end{cases}$$
클래스로 구현해보겠습니다.
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dxSigmoid 계층
시그모이드 함수의 식은 다음과 같습니다.
$$y = \frac{1}{1 + exp(-x)}$$
위 식을 계산 그래프로 나타내면 아래와 같습니다.
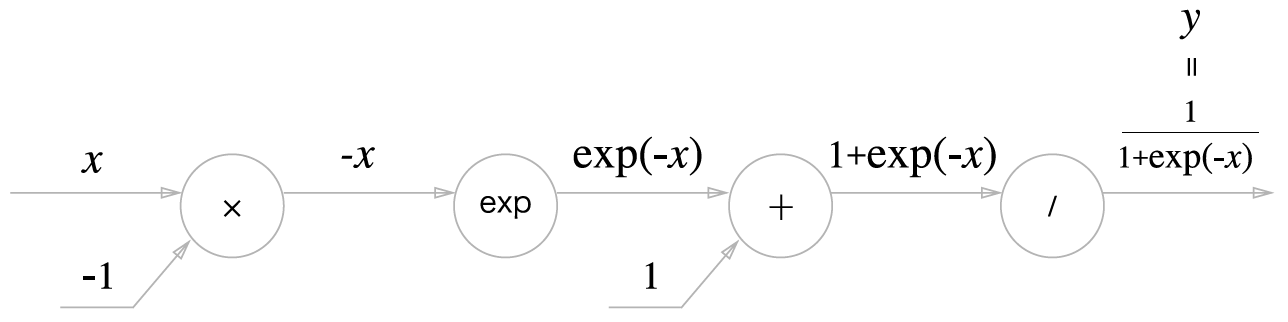
연쇄 법칙을 이용해 역전파를 계산 그래프를 그려보면 아래와 같습니다.

여기서 중간 과정을 생략하고 간략하게 나타내 보겠습니다.
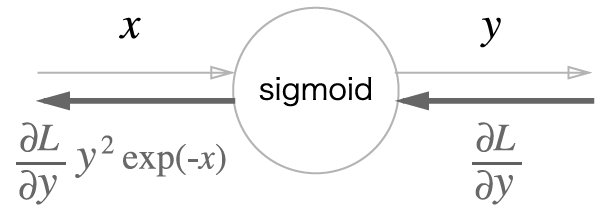
여기서 한 번 더 $\frac{\partial L}{\partial y} y^2 exp(-x)$를 정리해 보겠습니다.
\begin{align}
\frac{\partial L}{\partial y} y^2 exp(-x) & =\frac{\partial L}{\partial y} \frac{1}{(1+exp(-x))^2} exp(-x)\\
& =\frac{\partial L}{\partial y} \frac{1}{1+exp(-x)} \frac{exp(-x)}{1+exp(-x)}\\
& =\frac{\partial L}{\partial y} y(1-y)
\end{align}
이처럼 Sigmoid 계층의 역전파는 순전파의 출력($y$)만으로 계산할 수 있습니다.
파이썬 코드로 한 번 구현해보겠습니다.
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = 1 / (1 + np.exp(-x))
self.out = out
return out
def backward(self, dout):
dx = dout * ( 1.0 - self.out ) * self.out
return dxAffine / Softmax 계층 구현하기
Affine 계층
신경망의 순전파 때 수행하는 행렬의 곱은 기하학에서는 어파인 변환(affine transformation)이라고 합니다. 그래서 이 책에서 어파인 변환을 수행하는 처리를 'Affine 계층'이라는 이름으로 구현합니다.
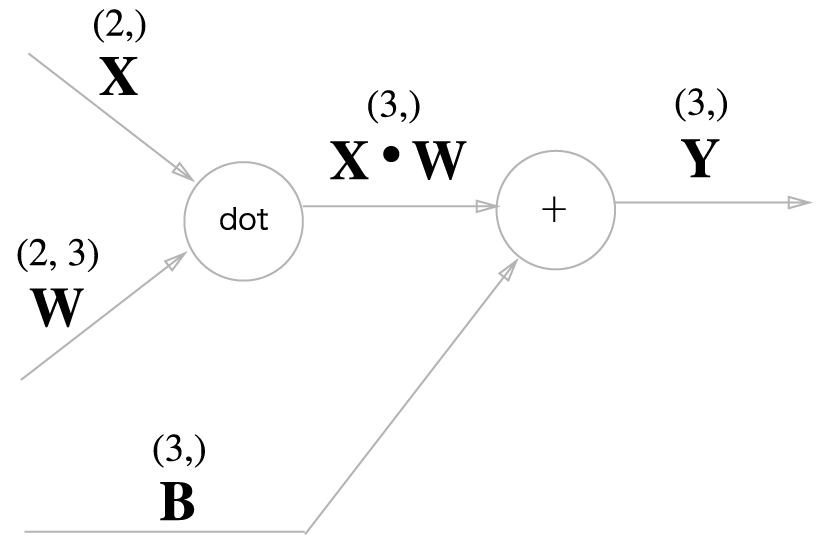
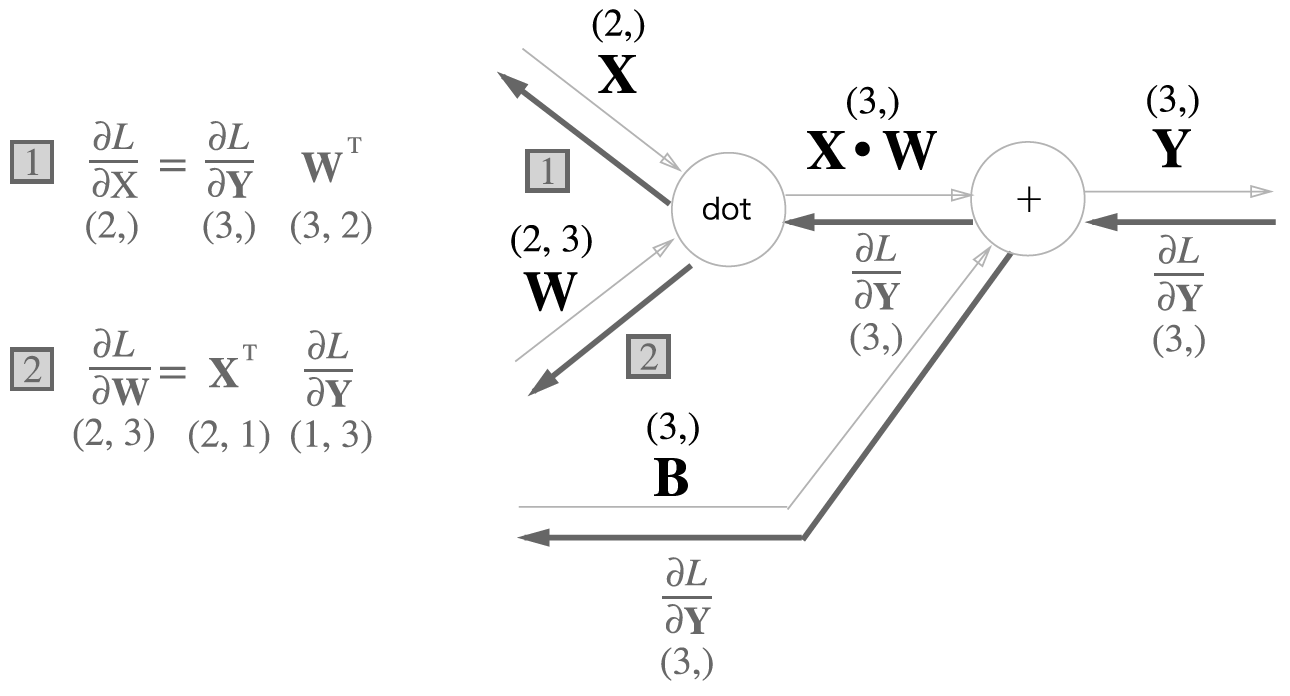
위 그래프에서 연쇄 법칙을 이용해 계산해보면 다음과 같은 식이 나옵니다.
\begin{align}
\frac{\partial L}{\partial X} & =\frac{\partial L}{\partial Y} \cdot W^T\\
\frac{\partial L}{\partial W} & = X^T \cdot \frac{\partial L}{\partial Y}\\
\end{align}
배치용 Affine 계층

그럼 Affine 계층을 파이썬으로 구현해보겠습니다.
class Affine:
def __init__(self, W, b):
self.W =W
self.b = b
self.x = None
self.original_x_shape = None
# 가중치 매개변수 미분
self.dW = None
self.db = None
def forward(self, x):
# 텐서 입력시
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = dx.reshape(*self.original_x_shape) # 입력데이터의 형상으로 복구(텐서 표현)
return dxSoftmax-with-Loss 계층
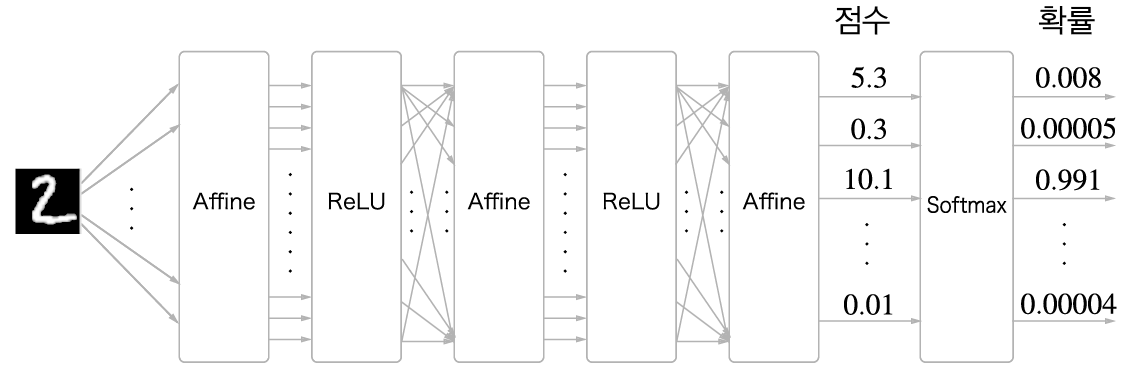
위 그림은 손글씨 숫자 인식에서의 Softmax 계층의 출력입니다. 입력 이미지가 Affine계층과 ReLU계층을 통과하며 변환되고, 마지막 Softmax 계층에 의해서 10개의 입력이 정규화됩니다.
이제 소프트맥스 계층을 구현할 텐데, 손실 함수인 교차 엔트로피 오차도 포함하여 'Softmax-with-Loss 계층'이라는 이름으로 구현합니다. 아래 그림은 'Softmax-with-Loss 계층'의 계산 그래프입니다.
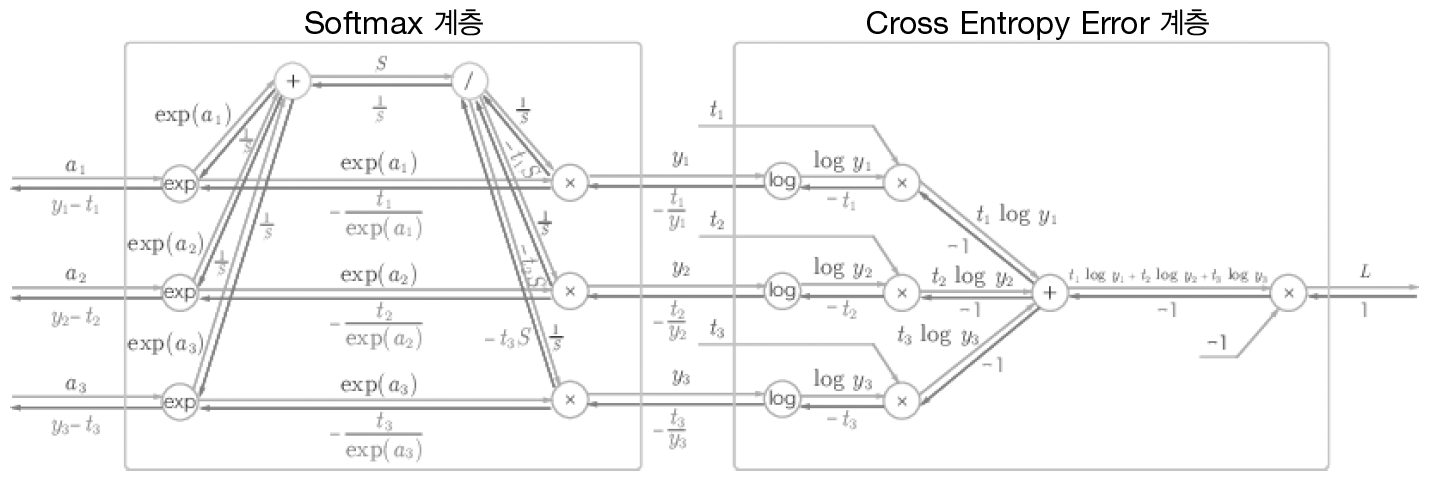
위 계산 그래프를 간소화하여 나타내겠습니다.
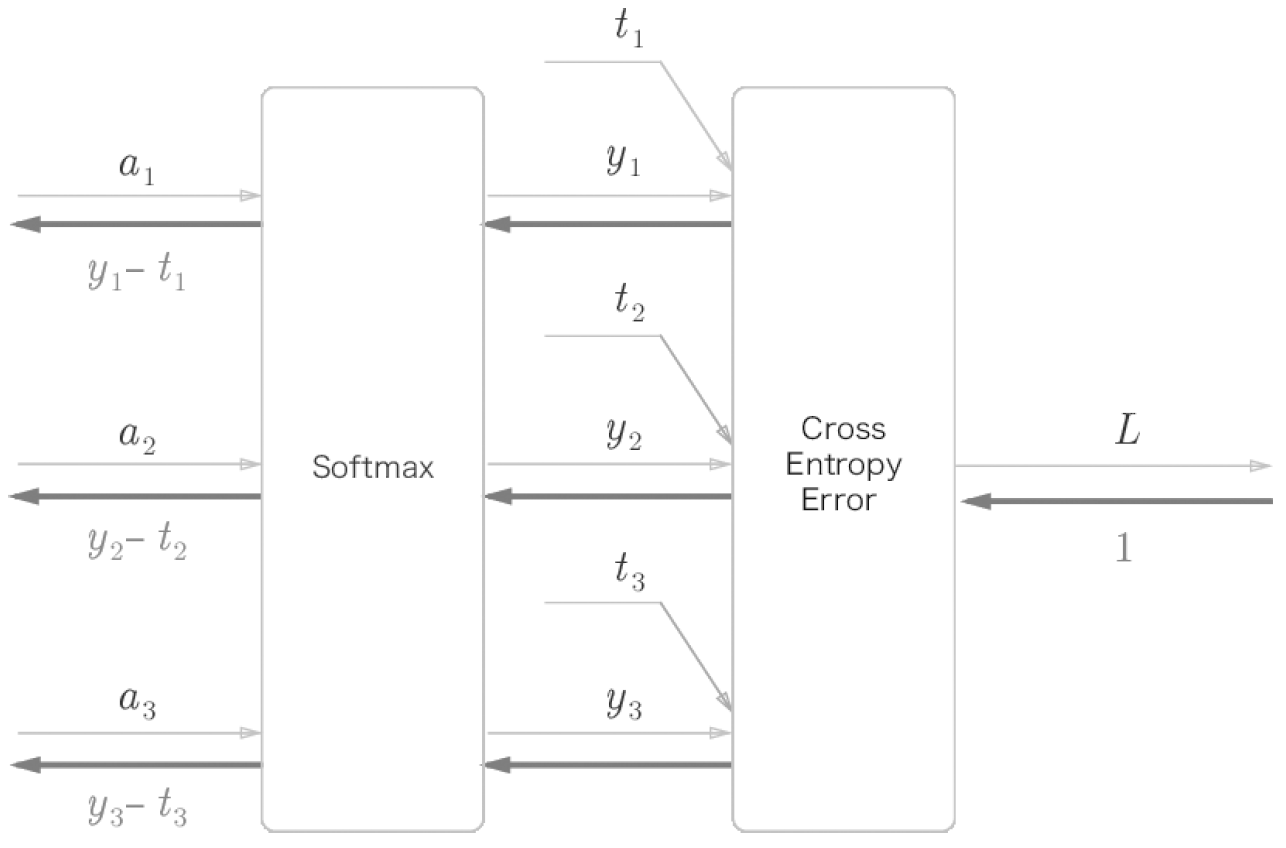
위 그림에서 알 수 있듯이 Softmax 계층의 역전파는 $(y_1 - t_1, y_2 - t_2, y_3, t_3)이라는 결과를 내놓고 있습니다. 이는 Softmax 계층의 출력과 정답 레이블의 차분입니다. 신경망의 역전파에서 이 차이인 오차가 앞 계층에 전해지는 것입니다.
이렇게 역전파의 결과가 깔끔하게 떨어지는 이유는 교차 엔트로피 오차 함수가 그렇게 설계되었기 때문입니다.
그럼 Softmax-with-Loss 계층을 구현한 코드를 보겠습니다.
class SoftmaxWithLoss:
def __init__(self):
self.loss = None # 손실
self.y = None # softmax의 출력
self.t = None # 정답 레이블(원-핫 벡터)
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
dx = (self.y - self.t) / batch_size
return dx오차 역전파법 구현하기
지금까지 구현한 계층을 조합해서 신경망을 구축해보겠습니다.
import sys, os
sys.path.append(os.pardir)
import numpy as np
from common.layers import *
from common.gradient import numerical_gradient
from collections import OrderDict
class TweLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 가중치 초기화
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 계층 생성
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layers.forward(x)
return x
# x : 입력 데이터, t : 정답 레이블
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y==t) / float(x.shape[0])
return accuracy
# x : 입력 데이터, t : 정답 레이블
def numerical_gradients(self, x, t):
loss_W = lambda W : self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
# 순전파
self.loss(x, t)
# 역전파
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 결과 저장
grads = {}
grads['W1'] = self.layers['Affine1'].dW
grads['b1'] = self.layers['Affine1'].db
grads['W2'] = self.layers['Affine2'].dW
grads['b2'] = self.layers['Affine2'].db
return grads기울기 검증하기
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
x_batch = x_train[:3]
t_batch = t_train[:3]
grad_numerical = network.numerical_gradient(x_batch, t_batch)
grad_backprop = network.gradient(x_batch, t_batch)
# 각 가중치의 차이의 절댓값을 구한 후, 그 절댓값들의 평균을 낸다.
for key in gran_numerical.keys():
diff = np.average(np.abs(grad_backprop[key] - grad_numerical[key]))
print(key + ':' + str(diff))오차역전파법을 사용한 학습 구현하기
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
#오차 역전파법으로 기울기를 구함
grad = network.gradient(x_batch, t_batch)
# 갱신
for key in ('W1', 'b1', 'W2' ,'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(train_acc, test_acc)5장에서는 계산 과정을 시각적으로 보여주는 방법인 계산 그래프를 배웠습니다. 계산 그래프를 이용하여 신경망의 동작과 오차역전파법을 설명하고, 그 처리 과정을 계층이라는 단위로 구현했습니다.
'AI > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| Chapter 7. 합성곱 신경망(CNN) (0) | 2022.09.16 |
|---|---|
| Chapter 4. 신경망 학습 (1) | 2022.09.16 |
| Chapter 3. 신경망 (0) | 2022.09.15 |
| Chapter 2. 퍼셉트론 (0) | 2022.09.15 |



