이 게시물은 밑바닥부터 시작하는 딥러닝 1권을 바탕으로 작성되었습니다.
이번 장의 주제는 합성곱 신경망(convolutional neural network, CNN)입니다.
전체 구조
지금까지 본 신경망은 인접하는 계층의 모든 뉴런과 결합되어 있었습니다.
이를 완전 연결(fully-connected, 전결합)이라고 하며, 완전히 연결된 계층을 Affine 계층이라는 이름으로 구현했습니다.
완전 연결 신경망은 Affine 계층 뒤에 활성화 함수를 갖는 ReLu 계층(혹은 Sigmoid 계층)이 이어집니다.
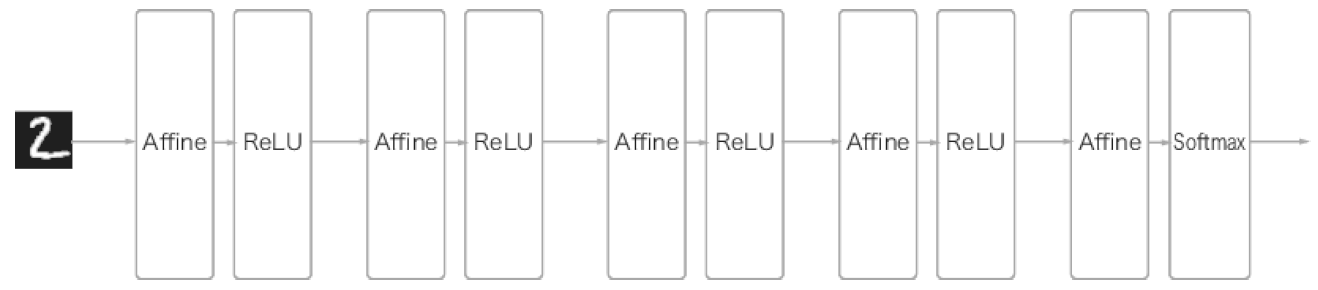
CNN의 구조는 다음과 같습니다.

- CNN에서는 새로운 합성곱 계층(Conv)과 풀링 계층(Pooling)이 추가됩니다.
- CNN의 계층은 ‘Conv-ReLu-(Pooling)’ 흐름으로 연결됩니다.( 풀링 계층은 생략하기도 함)
- 출력에 가까운 층에서는 지금까지의 ‘Affine-ReLu’ 구성을 사용할 수 있습니다.
합성곱 계층
CNN에서는 패딩(padding), 스트라이드(stride) 등 CNN 고유의 용어가 등장합니다. 각 계층 사이에는 3차원 데이터같이 입체적인 데이터가 흐른다는 점이 완전 연결 신경망과 다릅니다.
완전 연결 계층의 문제점
데이터의 형상(공간적인 정보)가 무시된다는 단점이 있습니다.
- 합성곱 계층은 형상을 유지합니다.
- 합성곱 계층의 입출력 데이터를 특징 맵(feature map)이라고도 부릅니다.
- 입력 데이터를 입력 특징 맵(input feature map), 출력 데이터를 출력 특징 맵(output feature map)이라고 부릅니다.
- 합성곱 연산은 이미지 처리에서 말하는 필터 연산에 해당합니다.
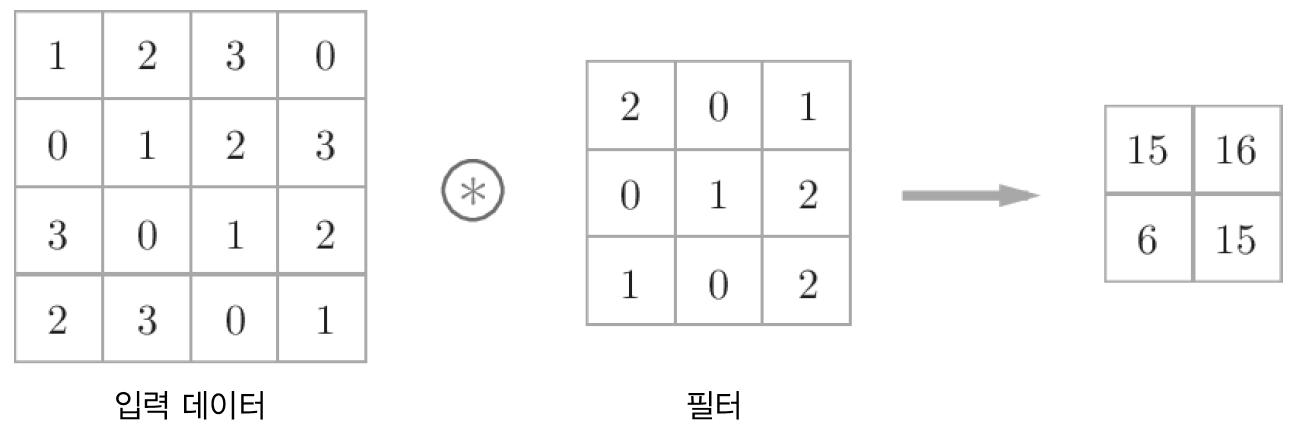
- 데이터와 필터의 형상을 (높이, 너비)로 표기합니다.
- 필터를 커널이라 칭하기도 합니다.
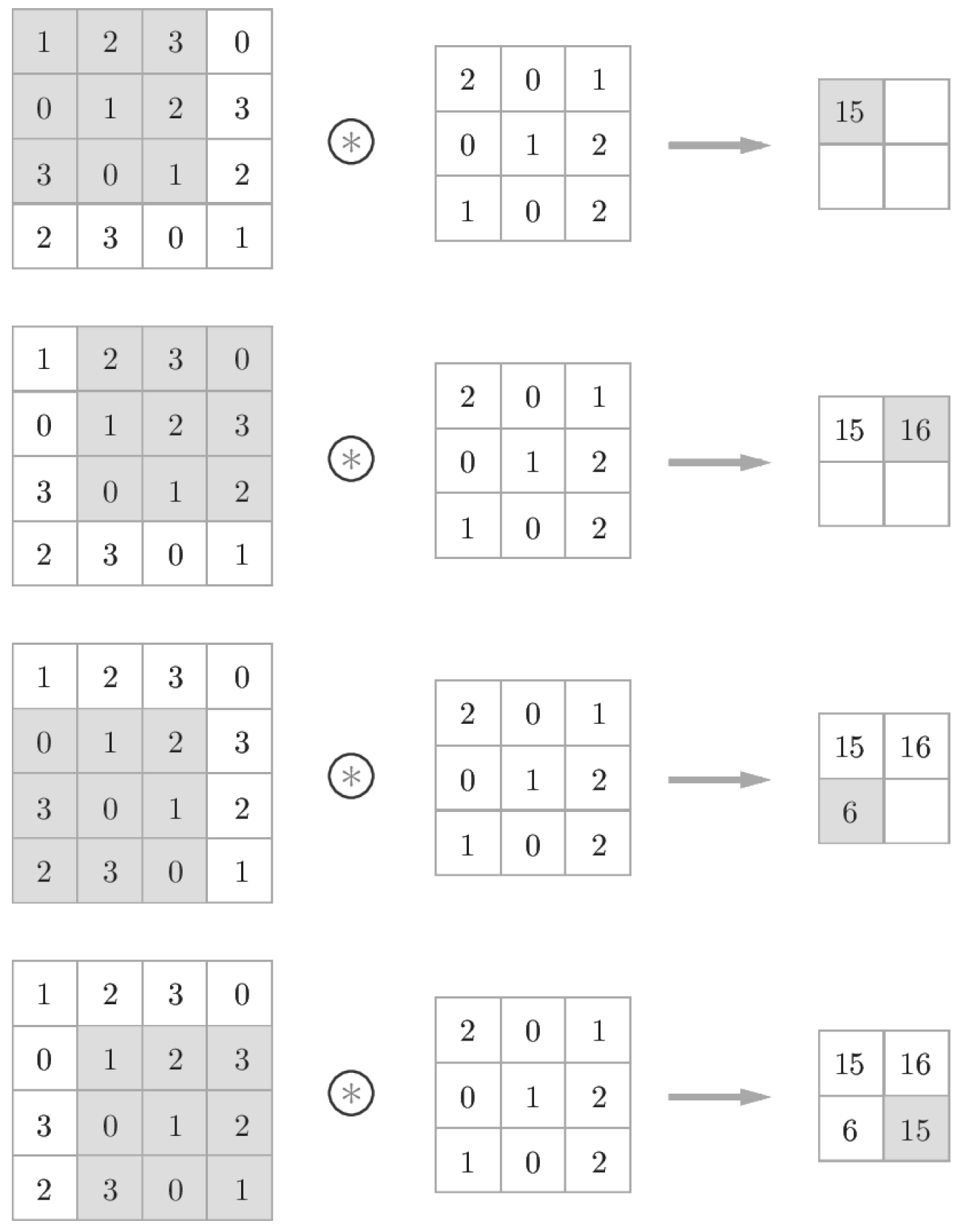
- 합성곱 연산은 필터의 윈도우(window)를 일정 간격으로 이동해가며 입력 데이터에 적용합니다.
- 입력과 필터에서 대응하는 원소끼리 곱한 후 그 총합을 구합니다.(단일 곱셉-누산이라고 부름)
- 합성곱에서 필터의 매개변수가 그동안의 '가중치'에 해당합니다.
| 합섭공과 교차 상관
합성곱 : 주어진 필터를 플리핑(flipping)합니다.
교차 상관 : 주어진 필터를 플리핑 하지 않고 그대로 사용합니다.
원래 둘은 다른 연산이지만 딥러닝에서는 잘 구분하지 않는 경향이 있습니다.
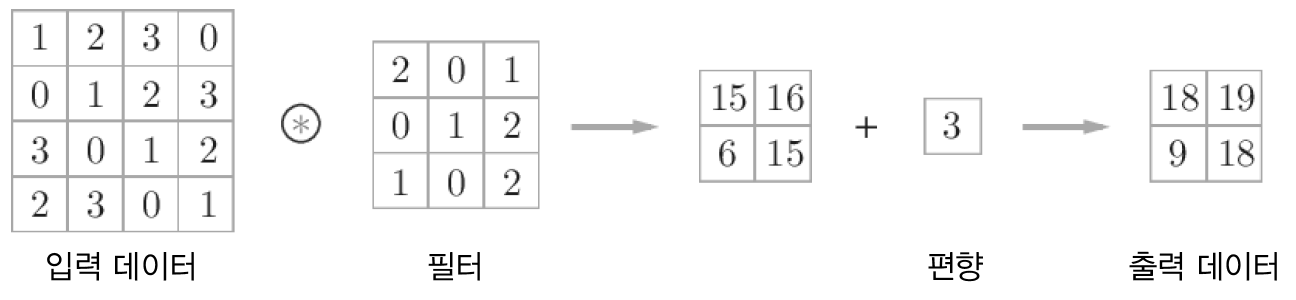
- 합성곱에서의 편향은 필터를 적용한 후의 데이터에 더해집니다. 그리고 편향은 항상 하나(1X1)만 존재합니다. 그 하나의 값을 필터를 적용한 모든 원소에 더하는 것입니다.
패딩
- 합성곱 연산을 수행하기 전에 입력 데이터 주변을 특정 값(예를 들어 0)으로 채우기도 합니다. 이를 패딩(padding)이라 합니다.
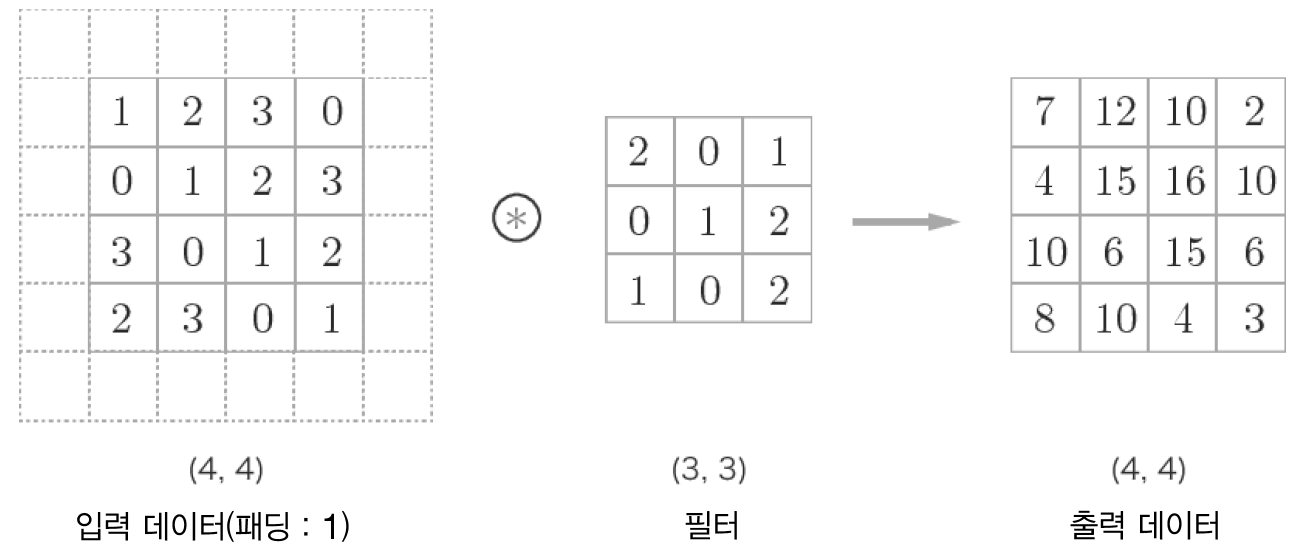
패딩은 주로 출력 크기를 조정할 목적으로 사용합니다. 만약 패딩이 없다면 출력의 사이즈가 줄어들게 되는데, 이는 합성곱 연산을 몇 번이나 되풀이하는 심층 신경망에서는 문제가 될 수 있습니다.
패딩을 사용함으로써 입력 데이터의 공간적 크기를 고정한 채로 다음 계층에 전달할 수 있습니다.
스트라이드
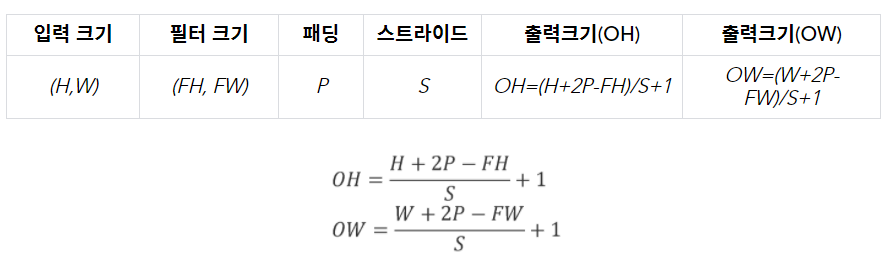
필터를 적용하는 위치의 간격을 스트라이드(stride)라고 합니다. 지금까지 본 예는 전부 스트라이드가 1이었지만. 예를 들어 스트라이드를 2로 하면 필터를 적용하는 윈도우가 두 칸씩 이동하게 됩니다.

패딩과 스트라이드의 크기에 따라 출력의 사이즈를 조절할 수 있습니다. 출력 사이즈는 아래 식에 따라 정해지게 됩니다.
3차원 데이터의 합성곱 연산
지금까지는 2차원 형상을 다루는 합성곱 연산을 살펴봤습니다. 하지만 이미지만 하더라도 세로, 가로에 더해서 채널(RGB)까지 고려한 3차원 데이터입니다. 이번엔 3차원 데이터를 다루는 합성곱 연산을 살펴보겠습니다.
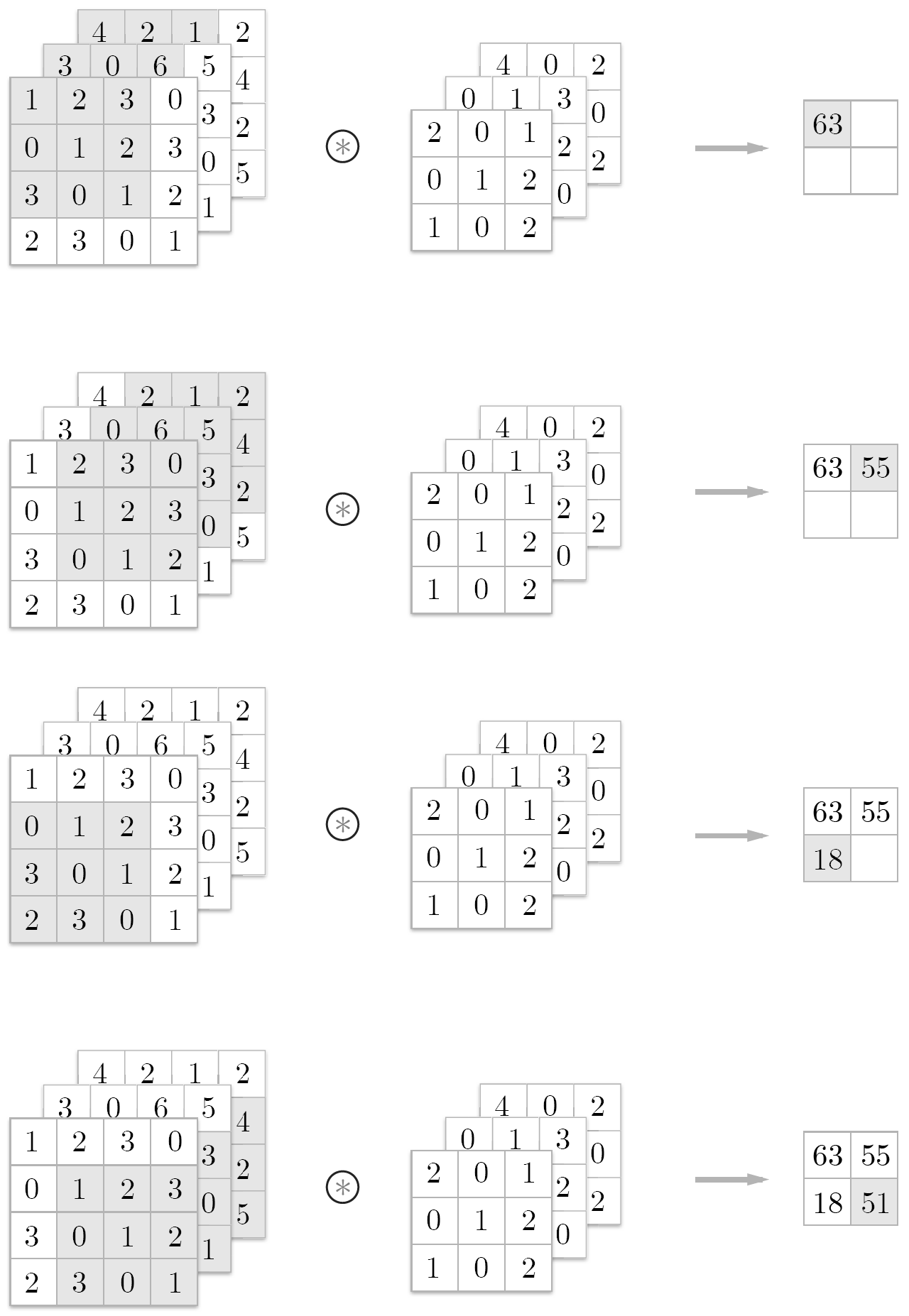
3차원 데이터에서 합성곱 연산을 수행할 때는 입력 데이터와 필터의 합성곱 연산을 채널마다 수행하고, 그 결과를 더해서 하나의 출력을 얻습니다.
여기서 주의해야할 점은 입력 데이터의 채널 수와 필터의 채널 수가 같아야 한다는 것입니다. 또한, 모든 채널의 필터가 같은 크기여야 합니다. 이 예에서는 필터의 크기가 (3,3)이지만 원한다면 (2, 2)나 (1, 1)로 설정할 수도 있습니다.
블록으로 생각하기
3차원 합성곱 연산은 데이터와 필터를 직육면체 블록이라고 생각하면 쉽습니다.
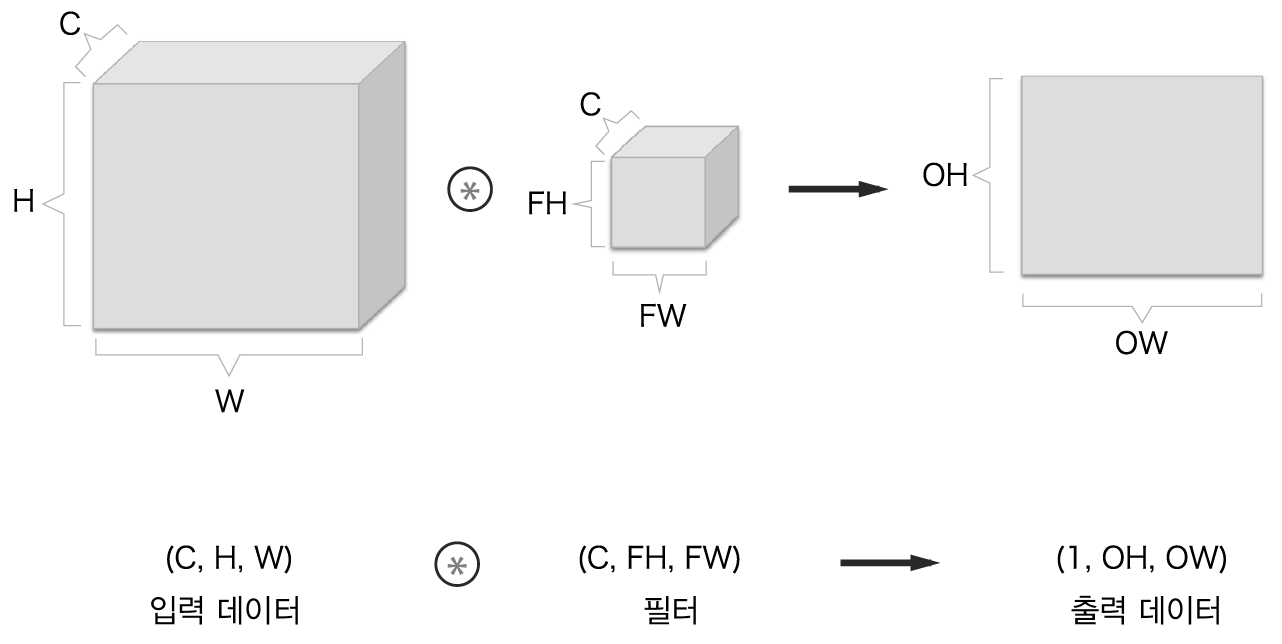
위 그림에서 출력 데이터는 한 장의 특징 맵입니다. 한 장의 특징 맵을 다른 말로 하면 채널이 1개인 특징 맵이라고 할 수 있습니다.
만약 합성곱 연산의 출력으로 다수의 채널을 내보내려면 아래 그림처럼 필터의 수를 늘리는 방법이 있습니다.
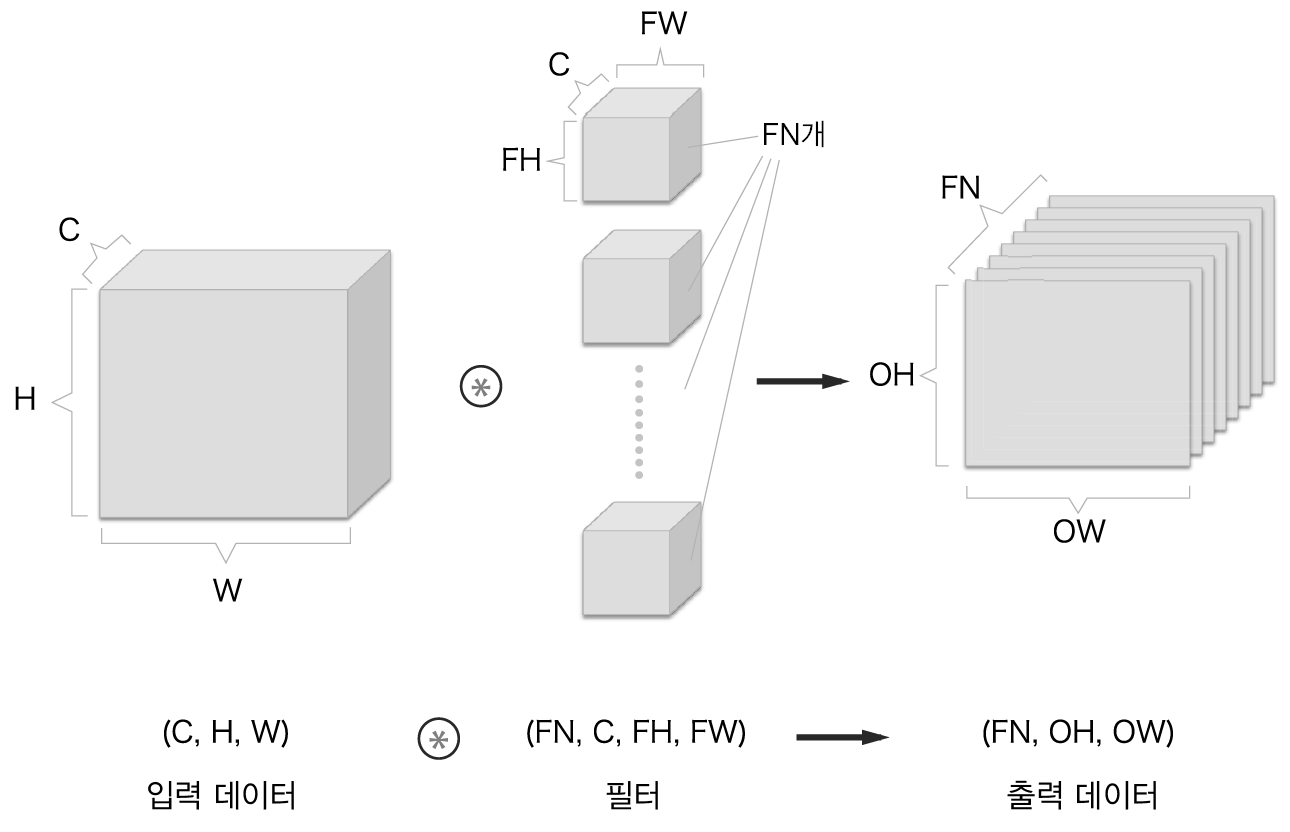
그림과 같이 필터를 FN개 적용하면 출력 맵도 FN개가 생깁니다.
또한, 합성곱 연산에도 (완전 연결 계층과 마찬가지로) 편향이 쓰입니다. 아래 그림은 합성곱 연산에 편향을 더한 모습입니다.
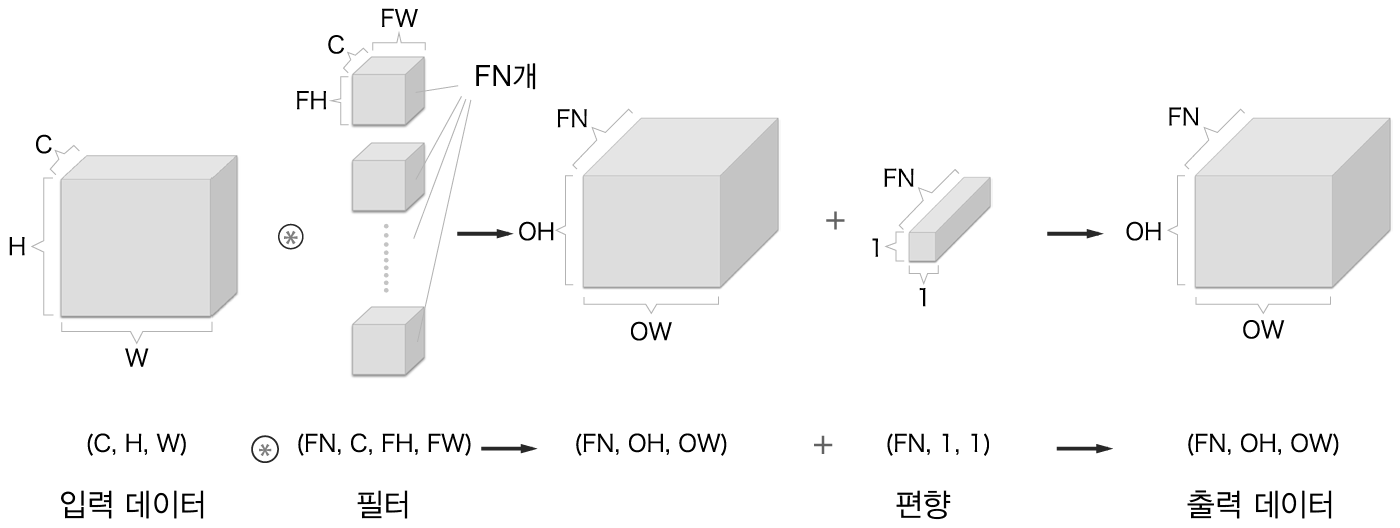
그림에서도 보이듯이 편향은 채널 하나에 값 하나씩으로 구성됩니다. 편향이 더해질 때에는 넘파이의 브로드캐스트 기능을 이용해 더해지게 됩니다.
배치 처리
신경망 처리에서는 입력 데이터를 한 덩어리로 묶어 배치로 처리했습니다.
합성곱 연산에서도 마찬가지로 배치 처리가 가능합니다.
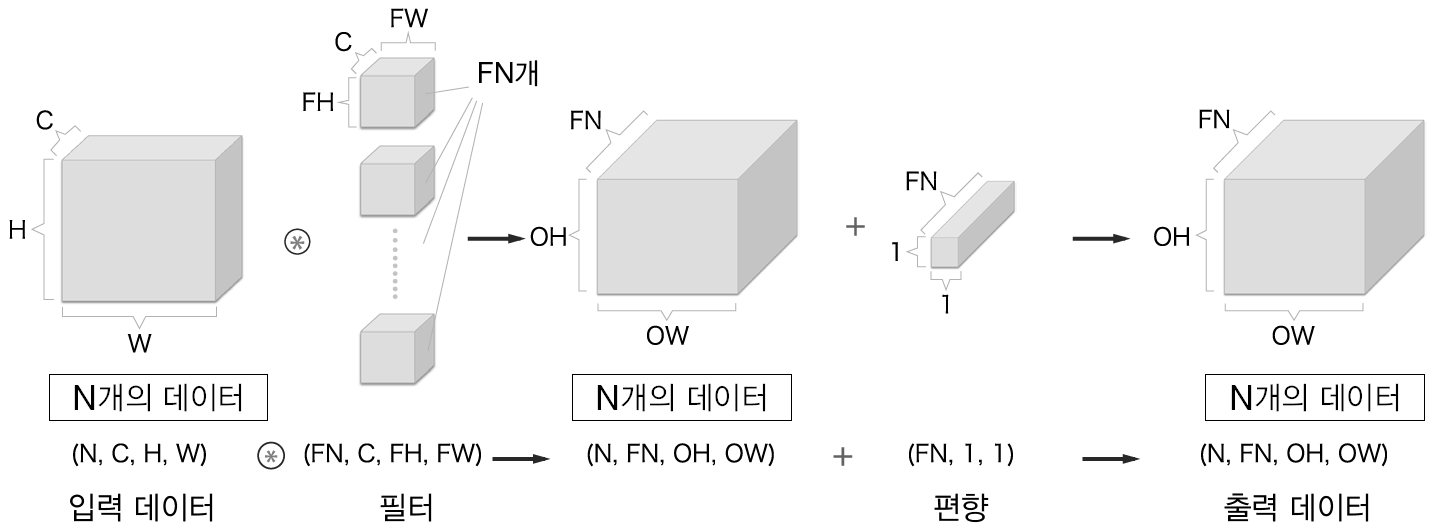
풀링 계층
풀링은 세로, 가로 방향의 공간을 줄이는 연산입니다.
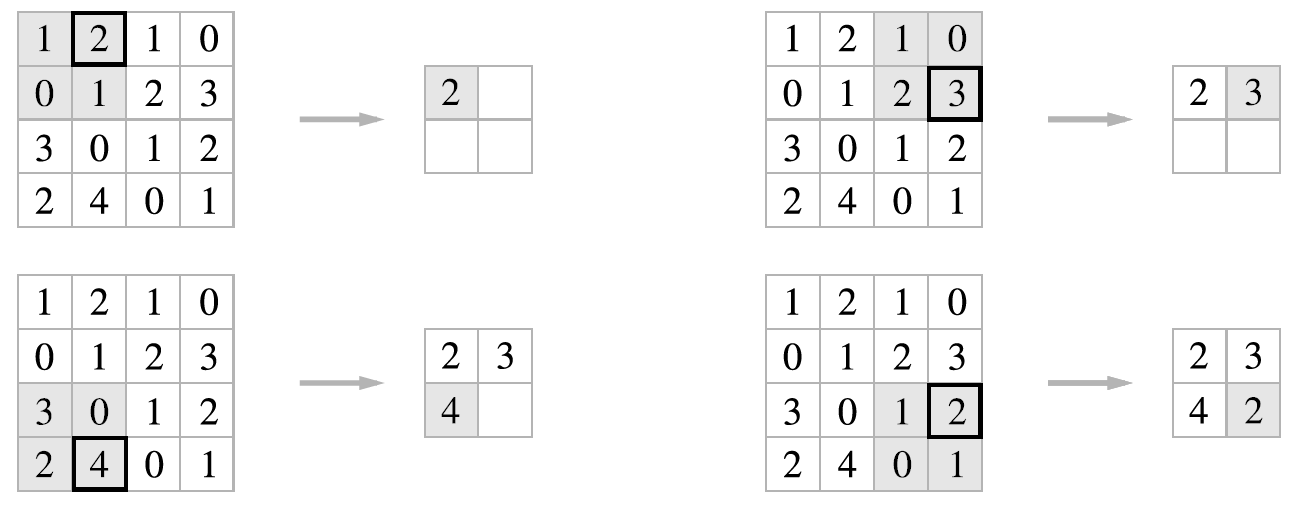
아래 그림은 2X2 최대 풀링(max pooling)을 스트라이드 2로 처리하는 순서입니다.
풀링 계층의 특징으로는 다음과 같은것이 있습니다.
- 학습해야 할 매개변수가 없다.
- 풀링은 대상 영역에서 최댓값이나 평균을 취하는 명확한 처리이므로 특별히 학습할 것이 없습니다.
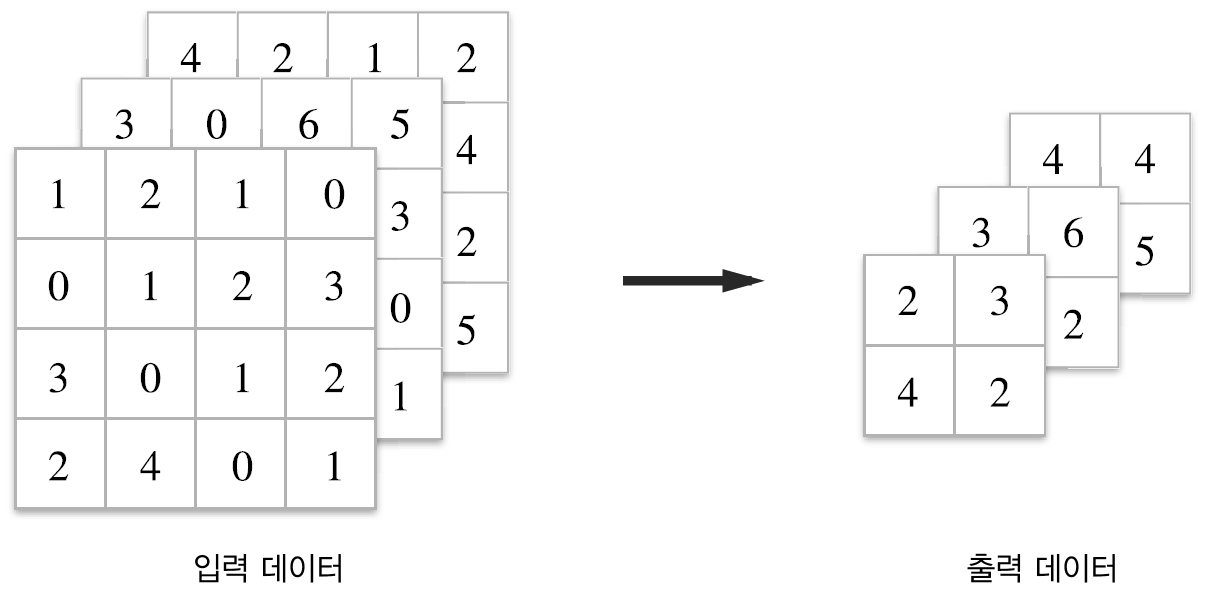
- 채널 수가 변하지 않는다.
- 풀링 연산은 입력 데이터의 채널 수 그대로 출력 데이터로 보냅니다. 아래 그림처럼 채널마다 독립적으로 계산하기 때문입니다.
- 입력의 변화에 영향을 적게 받는다(Robust 하다)
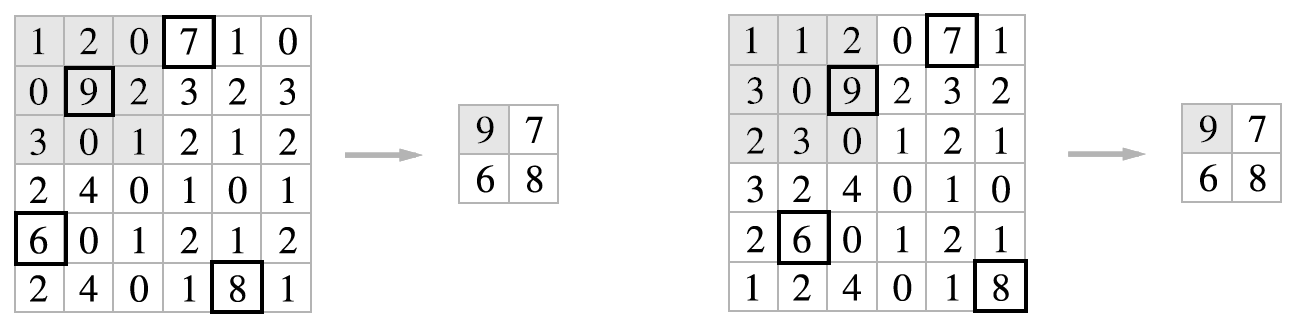
- 입력 데이터가 조금 변해도 풀링의 결과는 잘 변하지 않습니다. 예를 들어 아래 그림은 입력 데이터가 오른쪽으로 1칸씩 이동했지만 풀링 결과가 동일합니다.
하지만 모든 데이터에서 이런게 아니라 데이터에 따라서 다를 수도 있습니다. 웬만해서 Robust 하다 정도로 받아들이시면 될 것 같습니다.
- 입력 데이터가 조금 변해도 풀링의 결과는 잘 변하지 않습니다. 예를 들어 아래 그림은 입력 데이터가 오른쪽으로 1칸씩 이동했지만 풀링 결과가 동일합니다.
합성곱/풀링 계층 구현하기
im2col로 데이터 전개하기
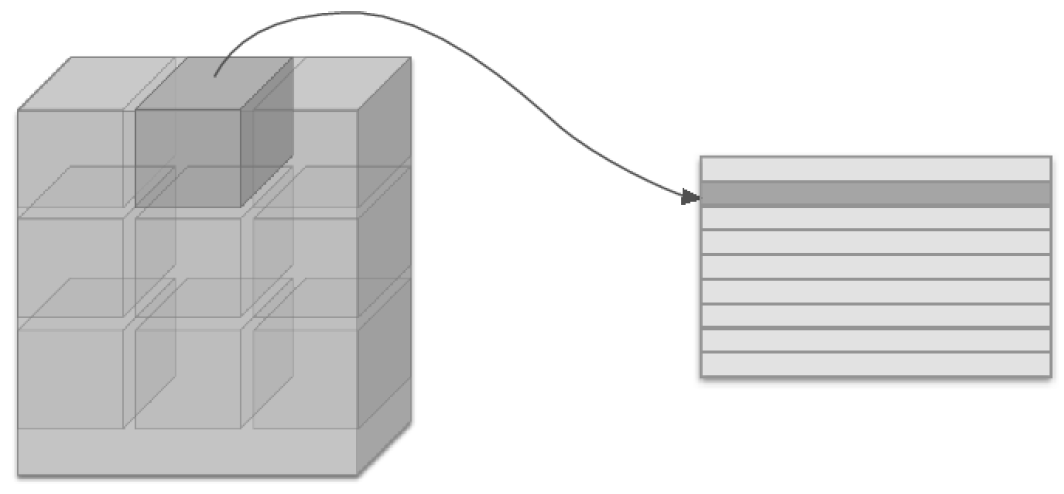
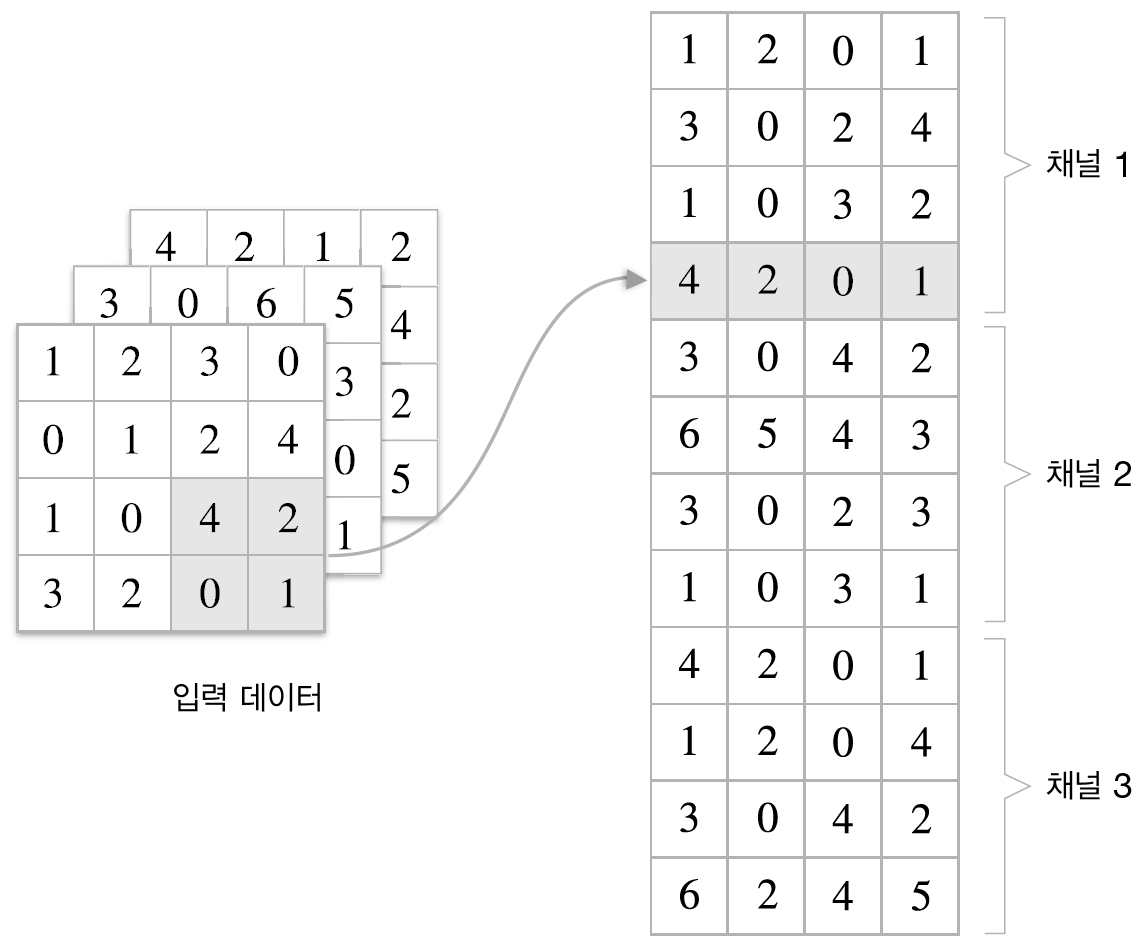
im2col은 입력 데이터를 가중치 계산하기 좋게 전개하는 함수입니다. 아래 그림과 같이 3차원 입력 데이터에 im2col을 적용하면 2차원 행렬로 바뀝니다.(정확히는 배치 안의 데이터 수까지 포함한 4차원 데이터를 2차원으로 변환합니다.)
그럼 아래 그림에서 im2col을 적용하여 전개한 데이터와 필터의 계산이 진행되는 과정을 보겠습니다.
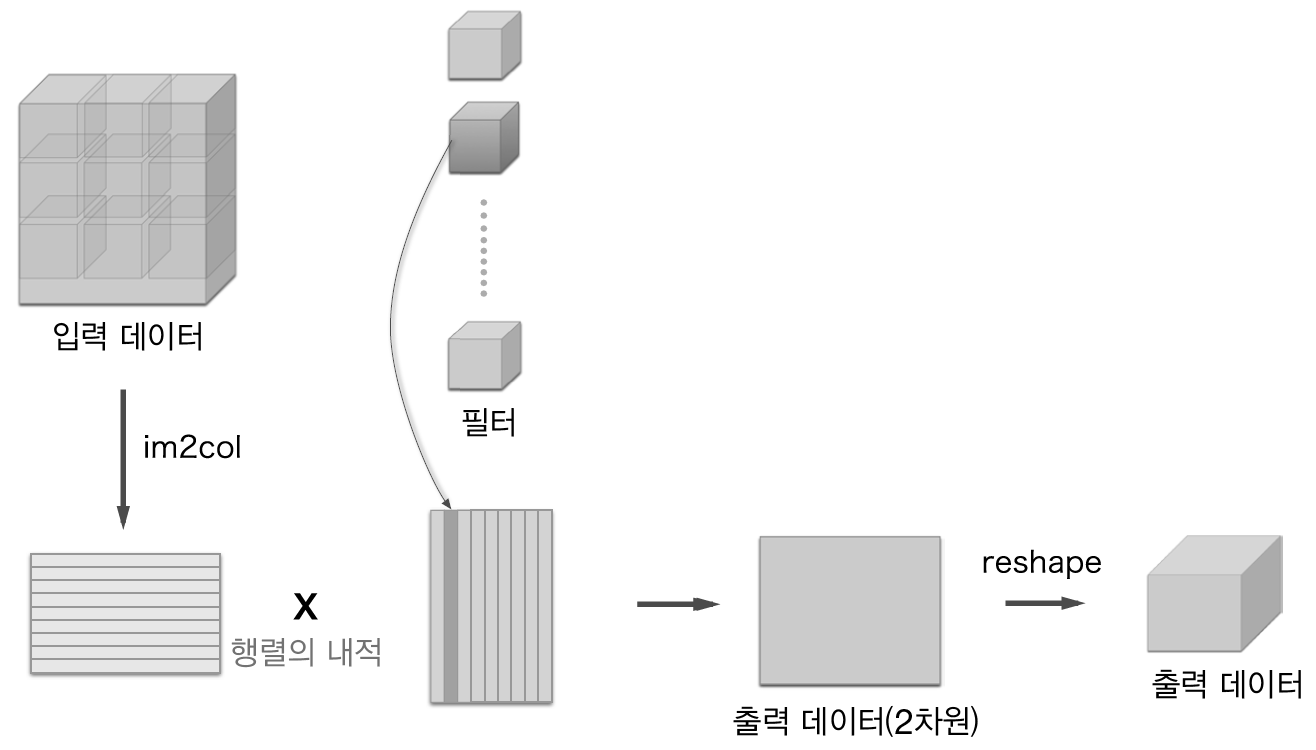
그럼 이 책에서 제공되는 im2col 함수를 이용해 합성곱 계층을 구현해보겠습니다.
im2col 함수의 인터페이스는 다음과 같습니다.
im2col(input_data, filter_h, filter_w, stride=1, pad=0)
- input_data : (데이터 수, 채널 수, 높이, 너비)의 4차원 배열로 이루어진 입력 데이터
- filter_h : 필터의 높이
- filter_w : 필터의 너비
- stride : 스트라이드
- pad : 패딩
import sys, os
sys.path.append(os.pardir)
from common.util import im2col
x1 = np.random.rand(1, 3, 7, 7) # ( 데이터 수, 채널 수, 높이, 너비)
col1 = im2col(x1, 5, 5, stride=1, pad=0)
print(col1.shape) # (9, 75)
x2 = np.random.rand(10, 3, 7, 7) # 데이터 10개
col2 = im2col(x2, 5, 5, stride=1, pad=0)
print(col2.shape) # (90, 75)이제 im2col을 사용하여 합성곱 계층을 구현해보겠습니다. 여기서는 합성곱 계층을 Convolution이라는 클래스로 구현하겠습니다.
class Convolution:
def __init__(self, W, b, stride=1, pad=0):
self.W = W
self.b = b
self.stride = stride
self.pad = pad
def forward(self, x):
FN, C, FH, FW = self.W.shape
N, C, H, W = x.shape
out_h = int(1+(H + 2*self.pad - FH) / self.stride)
out_w = int(1+(W + 2*self.pad - FW) / self.stride)
col = im2col(x, FH, FW, self.stride, self.pad)
col_W = self.W.reshape(FN, -1).T
out = np.dot(col, col_W) + self.b
out = out.reshape(N, out_h, out_w, -1).transpose(0,3,1,2)
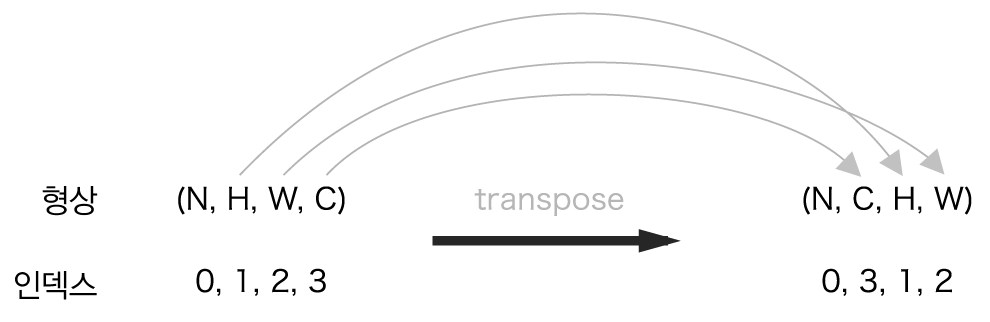
return out마지막 부분에 넘파이의 transpose 함수를 사용하는데, 이는 다차원 배열의 축 순서를 바꿔주는 함수입니다. 아래 그림과 같이 인덱스(0부터 시작)를 지정하여 축의 순서를 변경합니다.
풀링 계층 구현하기
풀링 계층 구현도 합성곱 계층과 마찬가지로 im2col을 사용해 입력 데이터를 전개합니다. 단, 풀링의 경우엔 채널 쪽이 독립적이라는 점이 합성곱 계층 때와 다릅니다.
일단 위와 같이 전개한 후, 전개한 행렬에서 행별 최댓값을 구하고 적절한 형상으로 reshape 해주면 됩니다.
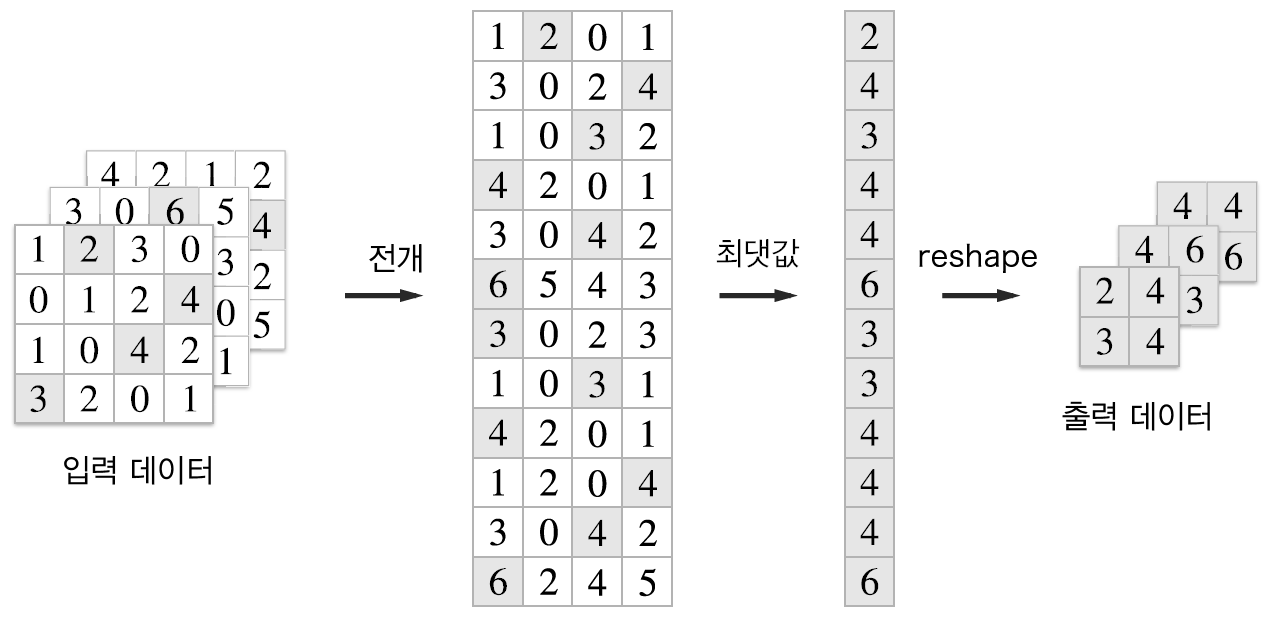
위 그림이 풀링 계층의 forward 처리 흐름입니다. 다음은 이를 파이썬으로 구현한 코드입니다.
class Pooling:
def __init__(self, pool_h, pool_w, stride=1, pad=0):
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
self.pad = pad
def forward(self, x):
N, C, H, W = x.shape
out_h = int(1+(H-self.pool_h)/self.stride)
out_w = int(1+(W-self.pool_w)/self.stride)
# 전개 (1)
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
col = col.reshape(-1, self.pool_h * self.pool_w)
# 최댓값 (2)
out = np.max(col, axis=1)
# reshape (3)
out = out.reshape(N, out_h, out_w, C).transpose(0,3,1,2)
return out위 코드는 세 단계로 진행됩니다.
- 입력 데이터 전개
- 행별 최댓값 구함
- 적절한 모양으로 reshape
CNN 구현하기
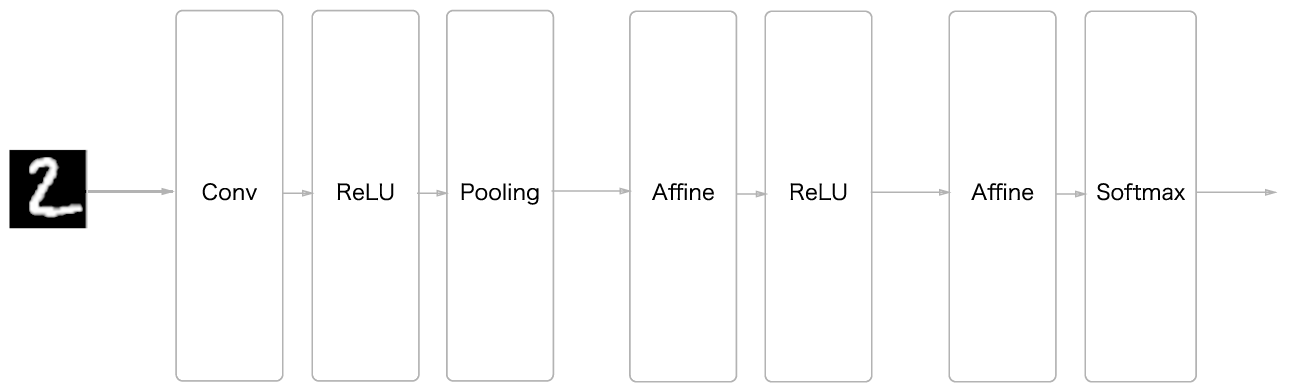
위 그림의 CNN 네트워크는
Convolution - ReLU - Pooling - Affine - ReLU - Affine - Softmax
순서로 흐릅니다. 이를 SimpltConvNet이라는 이름의 클래스로 구현하겠습니다.
class SimpleConvNet:
def __init__(self, input_dim=(1,28,28),
conv_params={'filter_num':30, 'filter_size':5,
'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size / 2) * (conv_output_size / 2))
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
self.layers = OrderDict()
self.layers['Conv1'] = Convolution(self.params['W1'],
self.params['b1'],
conv_param['stride'],
conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h = 2, pool_w = 2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'],
self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'],
self.params['b3'])
self.last_layer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x)
return self.last_layer.forward(y, t)
def gradient(self, x, t):
# 순전파
self.loss(x, t)
# 역전파
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.vackward(dout)
# 결과 저장
grads = {}
grads['W1'] = self.layers['Conv1'].dW
grads['b1'] = self.layers['Conv1'].db
grads['W2'] = self.layers['Affine1'].dW
grads['b2'] = self.layers['Affine1'].db
grads['W3'] = self.layers['Affine2'].dW
grads['b3'] = self.layers['Affine2'].db
return grads
이번 장에서는 CNN에 대해 배웠습니다.
솔직히 처음 볼 때도 그렇고, 정리를 하면서 다시 보면서도 느꼈지만 내용적으로는 간단해 보이는데 코드로 구현하면서 현기증이 났습니다...
충분한 시간을 가지고 코드를 하나하나 뜯어보면서 그 의미를 이해하는 과정을 반복해야 할 것 같습니다.
'AI > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| Chapter 5. 오차역전파법 (0) | 2022.09.16 |
|---|---|
| Chapter 4. 신경망 학습 (1) | 2022.09.16 |
| Chapter 3. 신경망 (0) | 2022.09.15 |
| Chapter 2. 퍼셉트론 (0) | 2022.09.15 |



