1. 데이터 준비와 확인
필요한 모듈 설치
!pip install konlpy
# install mecab-python
import os
os.chdir('/content')
!git clone https://bitbucket.org/eunjeon/mecab-python-0.996.git
os.chdir('/content/mecab-python-0.996')
!python3 setup.py build
!python3 setup.py install데이터 불러오고 확인
import pandas as pd
import konlpy
import gensim
train_data = pd.read_table('.../ratings_train.txt')
test_data = pd.read_table('.../ratings_test.txt')
train_data.head()
학습, 훈련 데이터 합치기
all_data = pd.concat([train_data, test_data], axis=0, ignore_index=True)
all_data.tail()중복치, 결측치 확인 후 제거
- 처음 결측치와 중복 치를 확인했을 때 중복 치는 0, 결측치는 document컬럼에서 8개가 있는 것을 알 수 있습니다.
- .dropna(axis =0)을 이용해 결측치가 존재하는 행을 전부 삭제해줍니다.
all_data.dropna(axis=0, inplace=True)로 삭제해도 결과는 같습니다. - 데이터 8개가 지워진 것을 볼 수 있습니다.
한국어 형태소 분석기 Mecab을 사용해 샘플 문장에 대해 토큰화를 진행해 보겠습니다.
sentence_list = list(all_data['document'])
from konlpy.tag import Mecab
tokenizer = Mecab()
tokenizer.morphs(sentence_list[0])2. 데이터 로더 구성
아래 기능이 있는 load_data 함수를 구현하겠습니다.
- 데이터의 중복 제거
- NaN 결측치 제거
- 한국어 토크나이저로 토큰화
- 불용어(Stopwords) 제거
- 사전 (word_to_index) 구성
- 텍스트 스트링을 사전 인덱스 스트링으로 변환
- x_train, y_train, x_test, y_test, word_to_index 리턴
from konlpy.tag import Mecab
import numpy as np
from collections import Counter
tokenizer = Mecab()
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
def load_data(train_data, test_data, num_words=15000):
# 데이터 전처리(가공)후에 다시 train, test 데이터로 나눠주기 위해 원래 train_data의 크기를 기억
len_train = len(train_data)
all_data = pd.concat([train_data, test_data], axis=0, ignore_index = True)
# 중복치와 결측치 제거
all_data = all_data.drop_duplicates('document', keep='first')
all_data = all_data.dropna(axis=0)
# 후기 문장들을 sentence_list에 list로 저장
sentence_list = list(all_data['document'])
# 형태소로 나눈 문장들을 리스트에 따로 저장
token_list = []
for sentence in sentence_list:
tokenize_sentence = tokenizer.morphs(sentence)
tokenize_sentence = [word for word in tokenize_sentence if word not in stopwords] # 불용어 제거
token_list.append(tokenize_sentence)
# 토큰화한 문장들을 train, test로 나눠줌
x_train = token_list[:len_train]
x_test = token_list[len_train:]
words = np.concatenate(x_train).tolist()
counter = Counter(words)
counter = counter.most_common(15000 - 4) # <pad>, <bos>, <unk>, <unused> 토큰을 추가해야하기 때문에 4개를 빼줌
vocab = ['<PAD>', '<BOS>', '<UNK>', '<UNUSED>'] + [key for key, _ in counter]
word2index = {word : index for index, word in enumerate(vocab)} # 단어를 정수 인덱스로 바꿔줌
def wordlist_to_indexlist(wordlist):
return [word2index[word] if word in word2index else word2index['<UNK>'] for word in wordlist]
x_train = list(map(wordlist_to_indexlist, x_train))
x_test = list(map(wordlist_to_indexlist, x_test))
return x_train, np.array(list(all_data['label'][:len_train])), x_test, np.array(list(all_data['label'][len_train:])), word2index
x_train, y_train, x_test, y_test, word2index = load_data(train_data, test_data)
index2word = {index : word for word, index in word2index.items()}# 문장 1개를 활용할 딕셔너리와 함께 주면 ,단어 인덱스 리스트 벡터로 변환해 주는 함수입니다.
# 단, 모든 문장은 <BOS>로 시작하는 것으로 합니다.
def get_encoded_sentence(sentence, word_to_index):
return [word_to_index['<BOS>']]+[word_to_index[word] if word in word_to_index else word_to_index['<UNK>'] for word in sentence.split()]
# 여러 개의 문장 리스트를 한꺼번에 단어 인덱스 리스트 벡터로 encode해주는 함수입니다.
def get_encoded_sentences(sentences, word_to_index):
return [get_encoded_sentence(sentence, word_to_index) for sentence in sentences]
# 숫자 벡터로 encode된 문장을 원래대로 decode하는 함수입니다.
def get_decoded_sentence(encoded_sentence, index_to_word):
return ' '.join(index_to_word[index] if index in index_to_word else '<UNK>' for index in encoded_sentence[1:])
# 여러 개의 숫자 벡터로 encode된 문장을 한꺼번에 원래대로 decode하는 함수입니다.
def get_decoded_sentences(encoded_sentences, index_to_word):
return [get_decoded_sentence(encoded_sentence, index_to_word) for encoded_sentence in encoded_sentences]3. 모델 구성을 위한 데이터 분석 및 가공
- 데이터셋 내 문장 길이 분포 확인
- 적절한 최대 문장 길이 지정
- keras.preprocessing.sequence.pad_sequences 함수를 활용해 패딩 추가
total_data_text = list(x_train) + list(x_test)
# 텍스트데이터 문장길이의 리스트를 생성
num_tokens = [len(tokens) for tokens in total_data_text]
num_tokens = np.array(num_tokens)
# 문장길이의 평균값, 최대값, 표준편차를 계산
print('문장길이 평균 : ', np.mean(num_tokens))
print('문장길이 최대 : ', np.max(num_tokens))
print('문장길이 표준편차 : ', np.std(num_tokens))
# 최대 길이를 (평균 + 2 * 표준편차) 로 한다면 남는 문장의 비율은?
max_tokens = np.mean(num_tokens) + 2 * np.std(num_tokens)
maxlen = int(max_tokens)
print('pad_sequences maxlen : ', maxlen)
print('전체 문장의 {}%가 maxlen 설정값 이내에 포함됩니다. '.format(np.sum(num_tokens < max_tokens) / len(num_tokens)))
import tensorflow as tf
# 문장의 마지막 입력이 최종 state에 영향을 가장 크게 미치기 때문에 패딩 적용은 pre(앞쪽)으로 해줍니다.
x_train = tf.keras.preprocessing.sequence.pad_sequences(x_train,
value=word2index['<PAD>'],
padding = 'pre',
maxlen = maxlen)
x_test = tf.keras.preprocessing.sequence.pad_sequences(X_test,
value=word2index["<PAD>"],
padding='pre',
maxlen=maxlen)
print(x_train.shape)
# output
(150000, 41)4. 모델 구성 및 Validation Set 구성
Validation Set은 train데이터의 10%로 설정하겠습니다. ( 15000개 )
val_x = x_train[:15000]
val_y = y_train[:15000]
x_train = x_train[15000:]
y_train = y_train[15000:]
print(x_train.shape, y_train.shape)
# output
(135000, 41) (135000,)LSTM
vocab_list = 15000
word_vector_dim = 100
model_lstm = tf.keras.Sequential()
model_lstm.add(tf.keras.layers.Embedding(vocab_size, word_vector_dim, input_shape=(None,)))
model_lstm.add(tf.keras.layers.LSTM(128, return_sequence=True))
model_lstm.add(tf.keras.layers.Dense(32, activation='relu'))
model_lstm.add(tf.keras.layers.LSTM(128, return_sequence=True))
model_lstm.add(tf.keras.layers.Dense(32, activation='relu'))
model_lstm.add(tf.keras.layers.LSTM(128))
model_lstm.add(tf.keras.layers.Dense(32, activation='relu'))
model_lstm.add(tf.keras.layers.Dense(1, activation='sigmoid')) # 최종 출력은 긍정/부정을 나타내는 1dim 입니다.
model_lstm.summary()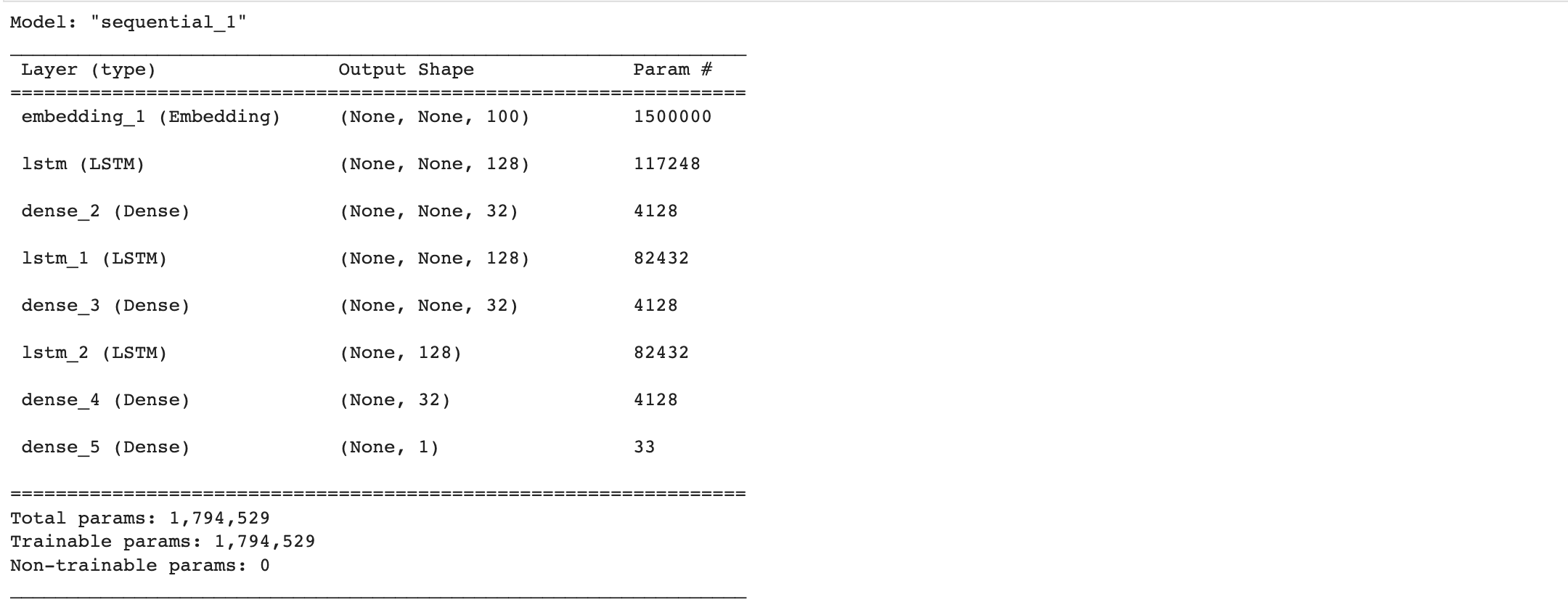
model_lstm.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs = 3
# 모델의 epoch 별 loss, accuracy, val_loss, val_accuracy를 저장하는 딕셔너리 생성하여 결과 시각화
history_lstm = model_lstm.fit(x_train,
y_train,
epochs=epochs,
batch_size=32,
validation_data=(val_x, val_y),
verbose=1)
테스트 데이터를 통해 모델의 훈련 결과를 한 번 보겠습니다.
results = model_lstm.evaluate(x_test, y_test, verbose=2)
print(results)
# output
1392/1392 - 7s - loss: 0.3338 - accuracy: 0.8634 - 7s/epoch - 5ms/step
[0.33384278416633606, 0.8634128570556641]훈련 과정을 시각화해보겠습니다.
loss의 변화나 accuracy의 변화를 살펴보겠습니다.
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) +1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()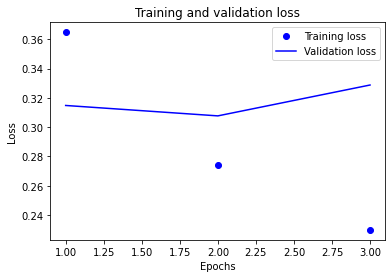
학습이....잘 안됐습니다.
단 2에폭 만에 과적합 되는 모습을 볼 수 있습니다.. ㅎㅎ
그래도 정확도 기준으로 시각화도 한 번 해보겠습니다.
plt.clf()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()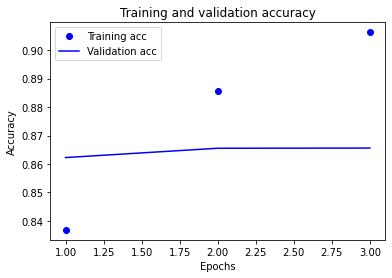
5. 사전 학습된 한국어 Word2Vec 임베딩 활용
from gensim.models.keyedvectors import Word2VecKeyedVectors
word2vec_file_path = '.../word2vec_ko.model'
word_vectors = Word2VecKeyedVectors.load(word2vec_file_path)
# 사전 학습된 임베딩 벡터는 차원이 100입니다.
vocab_size = 15000
word_vector_dim = 100
embedding_matrix = np.random.rand(vocab_size, word_vector_dim) # 사전학습 벡터를 복사할 더미를 만듭니다.
# embedding_matrix에 Word2Vec 워드 벡터를 단어 하나씩 차례대로 카피합니다.
for i in range(4, vocab_size):
if index2word[i] in word_vectors.wv:
embedding_matrix[i] = word_vectors.wv[index2word[i]]
# 모델 구성
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(vocab_size,
word_vector_dim,
embedding_initializer=tf.keras.initializers.Constant(embedding_matrix)
input_length=maxlen,
trainable=True)) # trainable=True로 주면 Fine-tuning
model.add(tf.keras.layers.Conv1D(64, 7, activation='relu'))
model.add(tf.keras.layers.MaxPooling1D(5))
model.add(tf.keras.layers.Conv1D(64, 7, activation='relu'))
model.add(tf.keras.layers.GlobalMaxPooling1D())
model.add(tf.keras.layers.Dense(32, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.summary()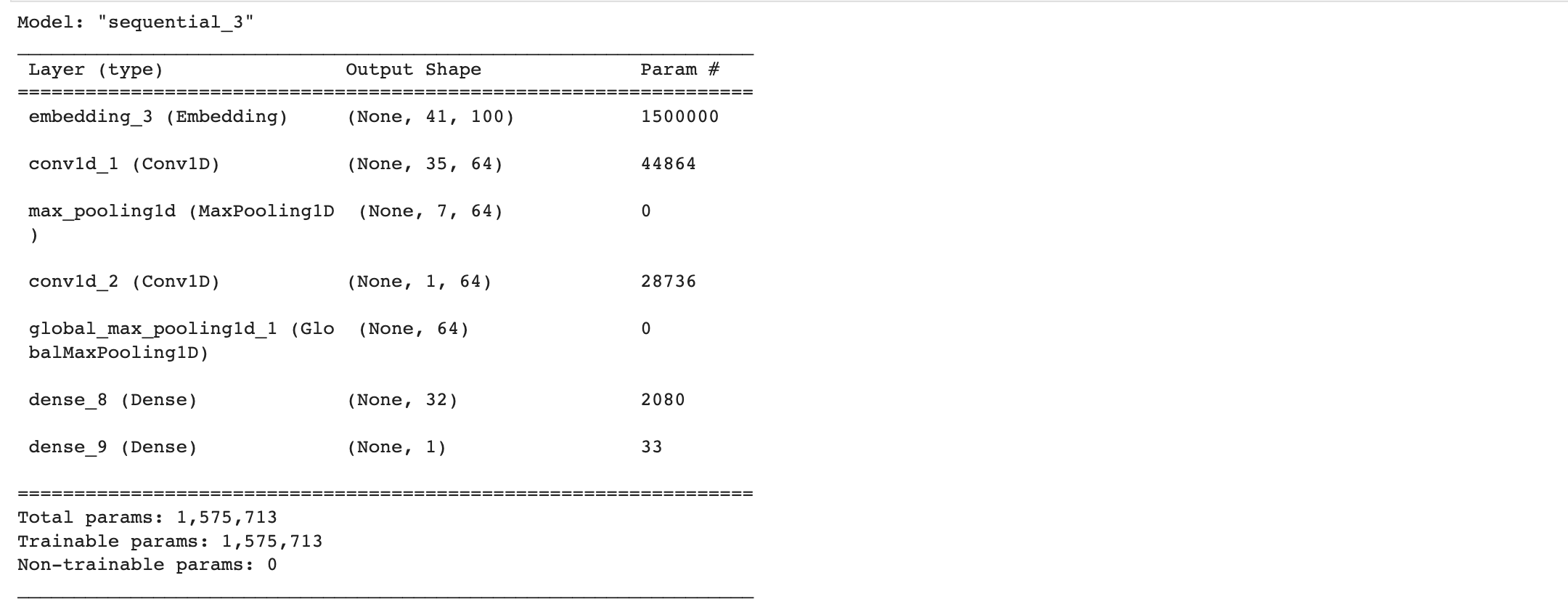
# 학습 진행
model.compile(optimizer = 'adam',
loss = 'binary_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train,
y_train,
epochs=3,
batch_size=32,
validation_data=(val_x, val_y),
verbose=1)
# 학습과정 시각화
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo"는 "파란색 점"입니다
plt.plot(epochs, loss, 'bo', label='Training loss')
# b는 "파란 실선"입니다
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()

plt.clf() # 그림을 초기화합니다
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()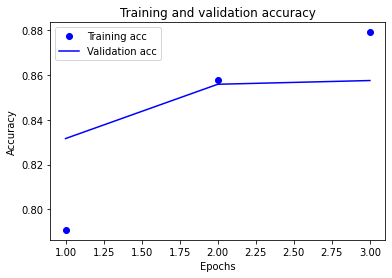
관련 이론
- 워드 임베딩
자연어 처리에서 임베딩은 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자 형태인 vector로 바꾼 결과 혹은 그 일련의 과정 전체를 의미합니다. 다시 말해, 단어를 밀집 벡터의 형태로 표현하는 방법을 워드 임베딩(word embedding)이라고 합니다. 그리고 이 밀집 벡터를 워드 임베딩 과정을 통해 나온 결과라고 하여 임베딩 벡터(embedding vector)라고도 합니다.

| 원-핫 벡터 | 임베딩 벡터 | |
| 차원 | 고차원(단어 집합의 크기) | 저차원 |
| 다른 표현 | 희소 벡터의 일종 | 밀집 벡터의 일종 |
| 표현 방법 | 수동 | 훈련 데이터로부터 학습함 |
| 값의 타입 | 1과 0 | 실수 |
01) 워드 임베딩(Word Embedding)
워드 임베딩(Word Embedding)은 단어를 벡터로 표현하는 방법으로, 단어를 밀집 표현으로 변환합니다. 희소 표현, 밀집 표현, 그리고 워드 임베딩에 대한 개념을 ...
wikidocs.net
2. 사전 훈련된 Word2Vec 임베딩
모델 다운로드 경로 : https://drive.google.com/file/d/0B7XkCwpI5KDYNlNUTTlSS21pQmM/edit
3. 1D CNN
임베딩 층을 거친 문장 형태의 행렬에 합성곱 신경망에서와 마찬가지로 필터를 이용해 합성곱 연산을 수행해주는 과정입니다.
여기서 필터(커널)의 너비는 문장 행렬에서의 임베딩 벡터의 차원과 동일하게 설정됩니다.
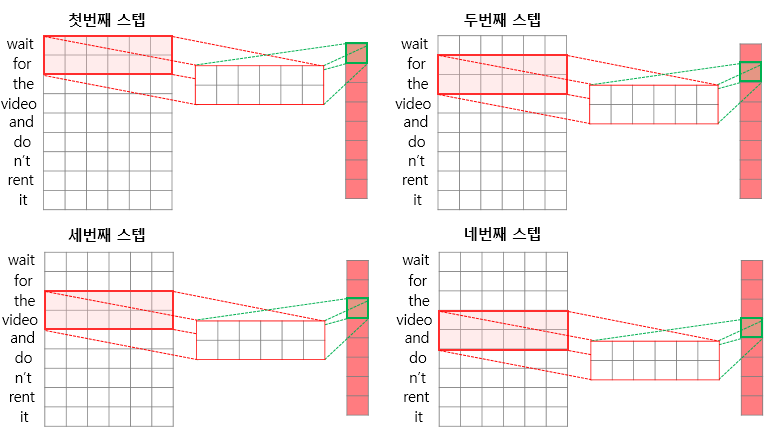
이런 과정을 거치는 합성곱 계층과 풀링 계층을 쌓아서 신경망을 설계하게 된다면 아래와 같은 모습이 됩니다.
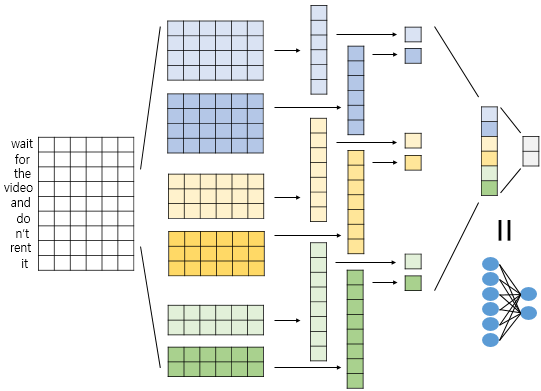
2) 자연어 처리를 위한 1D CNN(1D Convolutional Neural Networks)
합성곱 신경망을 자연어 처리에서 사용하기 위한 1D CNN을 이해해보겠습니다. ## 1. 2D 합성곱(2D Convolutions) 앞서 합성곱 신경망을 설명하며 합성곱 ...
wikidocs.net
4. LSTM
https://real-myeong.tistory.com/6?category=1081327
Lecture 10 : Recurrent Neural Networks
해당 게시물은 Standford 2017 CS231n 강의를 들으며 정리한 내용이며 슬라이드를 바탕으로 작성되었습니다. 이번 강의는 Recurrent Neural Networks에 관한 내용입니다. 위 그림은 RNN을 이용해서 만들 수 있
real-myeong.tistory.com
'AI > Toy Project' 카테고리의 다른 글
| [NLP] Attention을 이용하여 한-영 번역기 만들기 (0) | 2022.10.17 |
|---|---|
| 뉴스 요약봇 만들기 (1) | 2022.09.22 |
| seq2seq 모델을 이용한 번역기 만들기 (1) | 2022.09.22 |


