키워드 기반의 랭킹 알고리즘 BM25
BM25(a.k.a Okapi BM25)는 주어진 쿼리에 대해 문서와의 연관성을 평가하는 랭킹 함수로 사용되는 알고리즘으로, TF-IDF계열의 검색 알고리즘 중 SOTA인 것으로 알려져 있다.
엘라스틱서치에서도 유사도 알고리즘으로 BM25 알고리즘을 채택하였다.
BM25 계산
BM25에서 점수를 계산할 때는 아래와 같은 식을 사용하여 계산한다.
키워드 $[q_1, q_2, \ldots, q_n]$을 포함하는 쿼리 $Q$가 주어질 때 문서 $D$에 대한 BM25 점수 계산을 다음과 같다.
$$\begin{aligned} \text{score} (D, Q) &= \sum_{i=1}^n \text{IDF}(q_i) * \frac{f(q_i, D)*(k_1 +1)}{f(q_i, D) + k_1*(1 - b + b*\frac{|D|}{avgdl})}\\ \text{IDF}(q_i) &= \ln(\frac{N - n(q_i) + 0.5}{n(q_i) + 0.5} + 1)\end{aligned}$$
- $f(q_i, D)$ : 문서 D에서 $q_i$가 몇 번 등장했는지에 대한 값(TF)
- $|D|$ : 문서 D의 길이(토큰의 개수)
- $avgdl$ : 전체 데이터에서 문서들의 평균 길이
- $k_1, \; b$ : 파라미터. 보통 $k_1 \; \in [1.2, \; 2.0] \; \text{and} \; b = 0.75$
- $N$ : 전체 문서의 개수
- $n(q_i)$ : $q_i$를 포함하고 있는 문서의 개수
BM25 구현해 보기(직접)
import math
# IDF(qi)
def BM25_idf(data, token):
N = len(data)
n_qi = len([doc for doc in data if token in doc])
return math.log(((N-n_qi+0.5) / (n_qi+0.5)) + 1)
# f(qi, D)
def BM25_tf(token, doc):
qi_cnt = doc.count(token)
return qi_cnt
# score(D, Q)
def BM25_score(data, doc, query, k1 = 1.2, b=0.75):
doc_len = len(doc)
avgdl = sum([len(doc) for doc in data]) / len(data)
score = 0
for q in query:
idf_qi = BM25_idf(data, q)
f_qi = BM25_tf(q, doc)
score_qi = idf_qi * (f_qi *(k1+1)) / ((f_qi) + k1 * (1 - b + b *(doc_len/avgdl)))
score += score_qi
return score
# query가 주어질 때 해당 query와 데이터의 모든 문서에 대해서 bm25점수 계산
def get_bm25_score(query):
scores = []
for i in range(len(data)):
bm25_score = BM25_score(data = data, doc = data['tokenized'][i], query = query)
scores.append([i, bm25_score])
return scores영화 추천 기능을 위해 영화의 제목과 줄거리가 있는 데이터를 가져온다.
데이터는 여기서 movies_metadata.csv를 받아서 사용했다.
전처리는 영어 제외 전부 삭제, 소문자화, 띄어쓰기 단위로 토큰화 정도만을 진행했다.
import re
import pandas as pd
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
def simple_preprocessing(text):
text = text.strip()
text = text.lower()
text = re.sub(r'[^a-z]', ' ', text)
text = text.split()
return [word for word in text if word not in stop_words]
data = pd.read_csv('C:/Users/Myeong/dding/data/movies_metadata.csv', low_memory=False)
data = data[['title', 'overview']]
data.dropna(axis=0, inplace=True)
data.reset_index(inplace=True, drop=True)
data['tokenized'] = data['overview'].apply(lambda x : simple_preprocessing(x))
data
이제 영화의 제목을 입력하면 해당 영화의 줄거리와 가장 유사도가 높은 줄거리를 가진 영화 상위 10개를 리턴하는 함수를 정의하고, 몇 개의 영화 제목을 입력해서 나온 비슷한 영화 결과를 데이터프레임으로 뽑아서 확인해 준다.
def get_recommended_bm25(title):
# 해당 타이틀 영화의 토큰화된 overview를 가져온다.
tokenized = data[data['title']==title]['tokenized'].iloc[0]
# bm25 점수를 계산해준다
bm25_scores = get_bm25_score(tokenized)
# 점수가 높은 순서부터 내림차순으로 정렬 해준다.
sorted_scores = sorted(bm25_scores, reverse=True, key=lambda x : x[1])
# 점수 상위 10개의 인덱스 뽑아줌
top_10_idices = [idx[0] for idx in sorted_scores[1:11]]
# 상위 10개의 영화 제목 리턴한다
top_10_title = data['title'].iloc[top_10_idices]
top_10_list = top_10_title.to_list()
return top_10_listimport random
title_list = list(set(data['title'].to_list()))
title_list = random.sample(title_list, 4) + ['Toy Story']
recommended_list = []
for title in title_list:
top_10_list = get_recommended_bm25(title)
recommended_list.append(top_10_list)
df = pd.DataFrame(recommended_list, index=title_list)
df = df.transpose()
df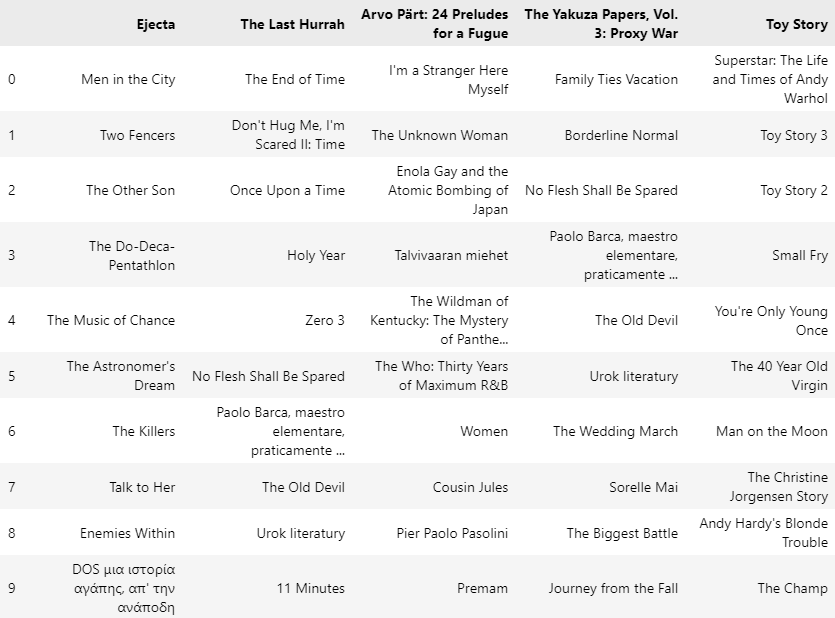
BM25 라이브러리 사용
직접 함수를 만들어서 사용하는 방법뿐 아니라 제공되는 라이브러리를 사용할 수도 있다.
나머지 과정은 똑같고 마지막에 get_recommended_bm25 함수 부분만 조금 차이가 있다.
from rank_bm25 import BM25Okapi
def get_recommended_bm25(title):
# 해당 타이틀 영화의 토큰화된 overview를 가져온다.
tokenized = data[data['title']==title]['tokenized'][0]
# bm25 점수를 계산해준다
bm25_scores = bm25.get_scores(tokenized)
# 점수가 높은 순서부터 내림차순으로 정렬 해준다.
# 인덱스도 같이 가져와야함
bm25_scores = [score for score in enumerate(bm25_scores)]
sorted_scores = sorted(bm25_scores, reverse=True, key=lambda x : x[1])
# 점수 상위 10개의 인덱스 뽑아줌
top_10_idices = [idx[0] for idx in sorted_scores[1:11]]
# 상위 10개의 영화 제목 리턴한다
return data['title'].iloc[top_10_idices]
get_recommended_bm25('Toy Story')
직접 구현해본 것과 라이브러리를 사용한 결과가 비슷하지만 조금 다른 것을 볼 수 있다.
이는 아마 라이브러리로 제공될 때 점수계산 방식의 디테일이 조금 차이가 있기 때문인 것 같다.
'AI > NLP Study' 카테고리의 다른 글
| [NLP] 임베딩 편향성 (0) | 2022.10.02 |
|---|---|
| [NLP] 워드 임베딩 (1) | 2022.10.01 |
| [NLP] 텍스트 카테고리 분류 (1) | 2022.09.29 |
| [NLP] 텍스트 벡터화 (0) | 2022.09.27 |
| [NLP] 단어사전 만들기 (1) | 2022.09.25 |



