이번에는 워드 임베딩에 숨어 있는 편향성을 측정하는 대표적인 방법론인 Word Embedding Association Test(WEAT)라는 기법에 대해 알아보고, 이를 활용해 직접 학습시킨 Word2Vec 임베딩 내의 편향성을 측정해 보면서 이 방법론이 우리의 편향성을 잘 반영하는지도 알아보겠습니다.

위 그림은 'Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings'라는 논문에 포함된 것입니다. 이 논문의 저자는 학습된 Word Embedding을 2차원으로 차원 축소하여 시각화했을 때, 젠더 중립적인 단어임에도 불구하고 Programmer, Doctor, Engineer 등의 단어는 남성 대명사 He에 가깝게, Homemaker, Nurse, Hairdresser 등의 단어는 여성 대명사 She에 가깝게 위치하는 것을 보여줍니다.
WEAT(Word Embedding Association Test)
Word Embedding Association Test는 임베딩 모델의 편향을 측정하는 방식 중 하나로, 2016년 Aylin Caliskan이 제안했습니다.
만약 Science와 Art가 모두 완벽히 젠더 중립적이라면, Word Embedding 상에서도 Science, Art가 Male, Female의 두 단어와의 거리가 동일해야 할 것입니다.
우리는 워드 임베딩 간의 거리를 코사인 유사도로 계산할 수 있다는 것을 알고 있으니, 그런 방식으로 계산해 보면 편향성을 쉽게 구할 수 있을 것 같습니다.
하지만 우리가 워드 임베딩 공간상에 편향이 존재한다고 단정하기 위해서는 앞에서처럼 단 4개의 단어로는 안될것입니다. 그래서 WEAT는 Male과 Female, Science와 Art라는 개념을 가장 잘 대표하는 단어들을 여러 개 골라 단어 셋(set)을 만듭니다.
이러한 단어 셋을 WEAT에서는 각각 target과 attribute라고 합니다.
위의 단어들로 예를 들면 Science를 대표하는 target 단어 셋 X와 Art를 대표하는 target 단어 셋 Y가 있다고 하면 X-Y 셋을 통한 개념 축 하나가 얻어집니다. Male을 대표하는 attribute단어 셋 A와 Female을 대표하는 attribute 단어 셋 B가 있다면 A-B 셋을 통한 개념 축 하나가 또 얻어집니다. 편향성이 없다면 X에 속한 단어들은 A에 속한 단어들과의 거리와 B에 속한 단어들과의 거리가 별 차이가 없어야 합니다. 반대의 경우라면 뚜렷한 차이가 있을 것입니다.
아래 표는 구글의 테크블로그에서 WEAT 개념을 소개하면서 첨부한 실험 결과표입니다.
Text Embedding Models Contain Bias. Here's Why That Matters.
News and insights on Google platforms, tools, and events.
developers.googleblog.com
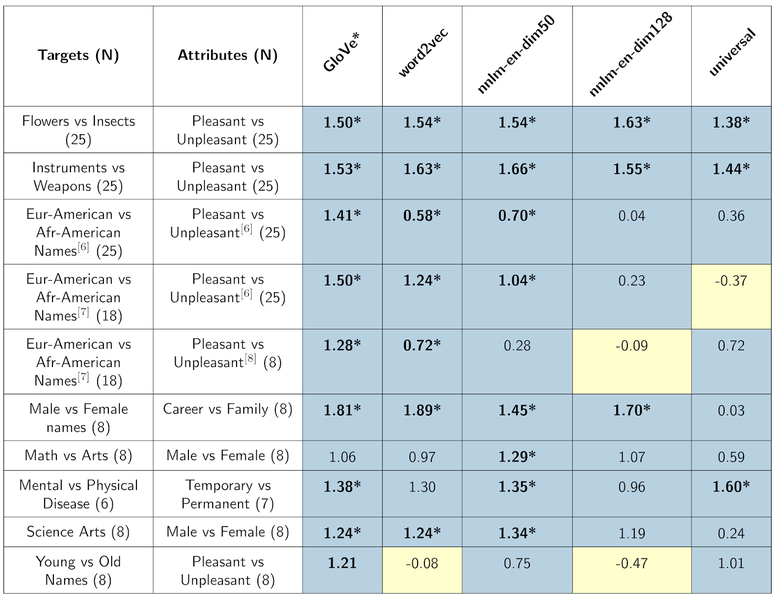
표에서 파란색은 인간의 편향과 같은 경우이고, 노란색은 인간의 편향과 반대인 경우를 의미합니다.
WEAT score는 다음과 같이 정의합니다.
$$\frac{mean_{x \in X}s(x, A, B) - mean_{y \in Y}s(y, A, B)}{std_{w \in X \cup Y}s(w, A, B)}$$
이 테스트는 두 벡터의 유사도를 측정하기 위해 cosine similarity를 이용합니다.
두 벡터 i, j가 주어지면 코사인 유사도 $cos(\theta)$는 dot product와 magnitude를 사용하여 구할 수 있습니다.
$$cos(\theta) = \frac{i \cdot j}{\| i \| \| j \|}$$
- $cos(\theta) = 1 $ : 두 벡터의 방향 동일
- $cos(\theta) = 0$ : 두 벡터 직교
- $cos(\theta) = -1$ : 두 벡터 방향 반대
코사인 유사도는 -1에서 1의 값을 가질 수 있으며 두 벡터의 방향이 얼마나 유사한지를 나타냅니다.
$$s(w, A, B) = mean_{a \in A}cos(\vec{w}, \vec{a}) - mean_{b \in B}cos(\vec{w}, \vec{b})$$
위 식의 $s(w, A, B)$가 의미하는 것은 target에 있는 단어 w가 두 attribute 셋 A, B에 속한 단어들과의 유사도의 평균값이 얼마나 차이 나는지를 측정합니다. 즉, $s(w, A, B)$는 개별 단어 w가 개념 축 A-B에 대해 가지는 편향성을 계산한 값입니다.
이 편향성 값은 -2 ~ 2의 값을 가지며, 그 절댓값이 클수록 w는 A-B 개념 축에 대해 편향성을 가진다는 뜻이 됩니다.
다시 WEAT score 식을 살펴보겠습니다.
$$\frac{mean_{x \in X}s(x, A, B) - mean_{y \in Y}s(y, A, B)}{std_{w \in X \cup Y}s(w, A, B)}$$
위 식의 분자 부분은 target X, Y에 속하는 각 단어 x, y들이 개념 축 A-B에 대해 가지는 각각의 편향성의 평균값을 뺀 값입니다.
때문에 X에 속하는 단어들과 Y에 속하는 단어들이 A-B 개념 축에 대해 가지는 편향성의 정도가 뚜렷하게 차이가 날수록 분자 값의 절댓값은 커지게 됩니다.
이 값을 X, Y에 속하는 모든 단어들이 가지는 편향성 값의 표준편차(std)로 normalize 한 값이 최종 WEAT score가 됩니다.
영화 장르 간 편향성 측정
위 내용을 영화 장르 간 편향성을 측정하면서 실제로 한 번 영화 장르 간에 내재된 편향성을 측정해보겠습니다.
실습은 google colab에서 진행했습니다.
1. 형태소 분석기를 이용하여 품사가 명사인 단어 추출
synopsis.txt에는 2001년부터 2019년 8월까지 제작된 영화들의 시놉시스 정보가 있습니다.
synopsis.txt 파일을 읽어 품사가 명사인 단어만을 tokenized라는 변수에 저장하겠습니다.
형태소 분석에는 konlpy에서 제공하는 Okt를 사용하겠습니다.
from konlpy.tag import Okt
okt = Okt()
tokenized = []
with open('/content/drive/MyDrive/AIFFEL/GoingDeeper_NLP/6_임베딩편향성/synopsis/synopsis.txt', 'r') as file:
while True:
line = file.readline()
if not line: break
words = okt.pos(line, stem=True, norm=True)
res = []
for w in words:
if w[1] in ["Noun"]: # "Adjective", "Verb" 등을 포함할 수도 있습니다.
res.append(w[0]) # 명사일 때만 tokenized 에 저장하게 됩니다.
tokenized.append(res)2. 추출된 결과로 embedding model 만들기
tokenized에 담긴 데이터를 이용하여 Word2Vec을 생성해줍니다.
from gensim.models import Word2Vec
model = Word2Vec(tokenized, vector_size=100, window=5, min_count=3, sg=0)잘 생성되었는지 몇 가지 단어를 이용해 확인해보겠습니다.


비슷한 단어를 잘 뽑아내는 거 보니 Word2Vec 훈련이 잘 된 것 같습니다.
3. TF-IDF로 해당 데이터를 가장 잘 표현하는 단어 셋 만들기
- 영화 구분
- synopsis_art.txt : 예술영화
- synopsis_gen.txt : 일반영화(상업영화)
- 그 외는 독립영화 등으로 분류됩니다.
- 장르 구분
- synopsis_SF.txt: SF
- synopsis_가족.txt: 가족
- synopsis_공연.txt: 공연
- synopsis_공포(호러).txt: 공포(호러)
- synopsis_기타.txt: 기타
- synopsis_다큐멘터리.txt: 다큐멘터리
- synopsis_드라마.txt: 드라마
- synopsis_멜로로맨스.txt: 멜로로맨스
- synopsis_뮤지컬.txt: 뮤지컬
- synopsis_미스터리.txt: 미스터리
- synopsis_범죄.txt: 범죄
- synopsis_사극.txt: 사극
- synopsis_서부극(웨스턴).txt: 서부극(웨스턴)
- synopsis_성인물(에로).txt: 성인물(에로)
- synopsis_스릴러.txt: 스릴러
- synopsis_애니메이션.txt: 애니메이션
- synopsis_액션.txt: 액션
- synopsis_어드벤처.txt: 어드벤처
- synopsis_전쟁.txt: 전쟁
- synopsis_코미디.txt: 코미디
- synopsis_판타지.txt: 판타지
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
from konlpy.tag import Okt
art_txt = 'synopsis_art.txt'
gen_txt = 'synopsis_gen.txt'
def read_token(file_name):
okt = Okt()
result = []
with open('.../synopsis/'+file_name, 'r') as fread:
print(file_name, '파일을 읽고 있습니다.')
while True:
line = fread.readline()
if not line: break
tokenlist = okt.pos(line, stem=True, norm=True)
for word in tokenlist:
if word[1] in ["Noun"]:#, "Adjective", "Verb"]:
result.append((word[0]))
return ' '.join(result)
art = read_token(art_txt)
gen = read_token(gen_txt)WEAT 계산을 위해서는 총 4개의 단어 셋 X, Y, A, B가 필요합니다.
TF-IDF방식을 이용해 단어 셋을 구성해주겠습니다.
먼저 art, gen을 이용해 두 개념 축 X, Y를 구성해주겠습니다.
# art, gen 이용해서 TF-IDF 만들기
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform([art, gen])
m1 = X[0].tocoo() # art를 TF-IDF로 표현한 sparse matrix를 가져옵니다.
m2 = X[1].tocoo() # gen을 TF-IDF로 표현한 sparse matrix를 가져옵니다.
w1 = [[i, j] for i, j in zip(m1.col, m1.data)]
w2 = [[i, j] for i, j in zip(m2.col, m2.data)]
w1.sort(key=lambda x: x[1], reverse=True) #art를 구성하는 단어들을 TF-IDF가 높은 순으로 정렬합니다.
w2.sort(key=lambda x: x[1], reverse=True) #gen을 구성하는 단어들을 TF-IDF가 높은 순으로 정렬합니다.
print('예술영화를 대표하는 단어들:')
for i in range(300):
print(vectorizer.get_feature_names_out()[w1[i][0]], end=', ')
print('\n')
print('일반영화를 대표하는 단어들:')
for i in range(300):
print(vectorizer.get_feature_names_out()[w2[i][0]], end=', ')
두 개념을 대표하는 단어를 TF-IDF가 높은 순으로 추출했습니다.
하지만 양쪽에 중복된 단어가 너무 많은 것을 볼 수 있습니다.
두 개념 축이 서로 대조되도록 대표하는 단어 셋을 만들기 위해 단어가 서로 중복되지 않게 단어 셋을 추출해줍니다.
상위 300개의 단어 중 중복되는 단어를 제외하고 상위 30개의 단어를 추출합니다.
n = 30
w1_, w2_ = [], []
for i in range(300):
w1_.append(vectorizer.get_feature_names_out()[w1[i][0]])
w2_.append(vectorizer.get_feature_names_out()[w2[i][0]])
# w1에만 있고 w2에는 없는, 예술영화를 잘 대표하는 단어를 30개 추출한다.
target_art, target_gen = [], []
for i in range(300):
if (w1_[i] not in w2_) and (w1_[i] in model.wv): target_art.append(w1_[i])
if len(target_art) == n: break
# w2에만 있고 w1에는 없는, 일반영화를 잘 대표하는 단어를 30개 추출한다.
for i in range(300):
if (w2_[i] not in w1_) and (w2_[i] in model.wv): target_gen.append(w2_[i])
if len(target_gen) == n: break
X, Y를 위해 art, gen에서 서로 중복되지 않으면서 가장 잘 표현해주는 단어들을 정해줬습니다.
이제는 모든 장르에 대해서도 동일한 방법으로 대표 단어들을 뽑아 보겠습니다.
genre_txt = ['synopsis_SF.txt', 'synopsis_family.txt', 'synopsis_show.txt', 'synopsis_horror.txt', 'synopsis_etc.txt',
'synopsis_documentary.txt', 'synopsis_drama.txt', 'synopsis_romance.txt', 'synopsis_musical.txt',
'synopsis_mystery.txt', 'synopsis_crime.txt', 'synopsis_historical.txt', 'synopsis_western.txt',
'synopsis_adult.txt', 'synopsis_thriller.txt', 'synopsis_animation.txt', 'synopsis_action.txt',
'synopsis_adventure.txt', 'synopsis_war.txt', 'synopsis_comedy.txt', 'synopsis_fantasy.txt']
genre_name = ['SF', '가족', '공연', '공포(호러)', '기타', '다큐멘터리', '드라마', '멜로로맨스', '뮤지컬', '미스터리', '범죄', '사극', '서부극(웨스턴)',
'성인물(에로)', '스릴러', '애니메이션', '액션', '어드벤처', '전쟁', '코미디', '판타지']
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
from konlpy.tag import Okt
def read_token(file_name):
okt = Okt()
result = []
with open('.../synopsis/'+file_name, 'r') as fread:
print(file_name, '파일을 읽고 있습니다.')
while True:
line = fread.readline()
if not line: break
tokenlist = okt.pos(line, stem=True, norm=True)
for word in tokenlist:
if word[1] in ["Noun"]:#, "Adjective", "Verb"]:
result.append((word[0]))
return ' '.join(result)
# 장르에 해당하는 TF-IDF 만들어줌
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(genre)
m = [X[i].tocoo() for i in range(X.shape[0])]
w = [[[i, j] for i, j in zip(mm.col, mm.data)] for mm in m]
for i in range(len(w)):
w[i].sort(key=lambda x: x[1], reverse=True)
attributes = []
for i in range(len(w)):
print(genre_name[i], end=': ')
attr = []
j = 0
while (len(attr) < 30):
if vectorizer.get_feature_names_out()[w[i][j][0]] in model.wv:
attr.append(vectorizer.get_feature_names_out()[w[i][j][0]])
print(vectorizer.get_feature_names_out()[w[i][j][0]], end=', ')
j += 1
attributes.append(attr)
print()
4. WEAT score 계산과 시각화
이제 WEAT_score를 구해보겠습니다.
target_X는 art, target_Y는 gen, attribute_A는 '드라마', attribute_B는 '액션'과 같이 정해줄 수 있습니다.
현재 총 21개의 장르에 대해 계산해야 하기 때문에 계산 결과를 21 x 21 매트릭스 형태로 표현해서 matrix라는 변수에 담아 주겠습니다.
먼저 WEAT score를 구하는 함수를 정의해주겠습니다.
import numpy as np
from numpy import dot
from numpy.linalg import norm
def cos_sim(i, j):
return dot(i, j.T)/(norm(i)*norm(j))
def s(w, A, B):
c_a = cos_sim(w, A)
c_b = cos_sim(w, B)
mean_A = np.mean(c_a, axis=-1)
mean_B = np.mean(c_b, axis=-1)
return mean_A - mean_B #, c_a, c_b
def weat_score(X, Y, A, B):
s_X = s(X, A, B)
s_Y = s(Y, A, B)
mean_X = np.mean(s_X)
mean_Y = np.mean(s_Y)
std_dev = np.std(np.concatenate([s_X, s_Y], axis=0))
return (mean_X-mean_Y)/std_dev함수를 정의했으니 개념 축 X, Y에 대해 A, B를 바꿔가며 WEAT score를 계산하고 각 결과를 21x21 크기의 matrix에 기록해주겠습니다.
# 21 x 21 matrix 생성
matrix = [[0 for _ in range(len(genre_name))] for _ in range(len(genre_name))]
X = np.array([model.wv[word] for word in target_art])
Y = np.array([model.wv[word] for word in target_gen])
for i in range(len(genre_name)-1):
for j in range(i+1, len(genre_name)):
A = np.array([model.wv[word] for word in attributes[i]])
B = np.array([model.wv[word] for word in attributes[j]])
matrix[i][j] = weat_score(X, Y, A, B)matrix를 채웠으니 결과를 한 번 확인해보고 편향에 대해 해석해보겠습니다.
for i in range(1):
for j in range(i+1, 6):
print(genre_name[i], genre_name[j],matrix[i][j])
위 결과를 한 번 해석해보면 다음과 같습니다.
- 예술 영화와 일반 영화, 그리고 SF와 가족의 WEAT score의 의미를 해석하면 예술 영화는 가족, 일반 영화는 SF와 가깝다고 볼 수 있습니다. 부호가 마이너스이므로 사람의 편향과 반대라는 것을 알 수 있습니다.
- 예술 영화와 일반 영화, 그리고 SF와 다큐멘터리의 WEAT score의 의미를 해석하면 예술 영화는 SF, 일반 영화는 다큐멘터리와 가깝다고 볼 수 있습니다.
히트맵을 이용해 시각화해보겠습니다.
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
np.random.seed(0)
# 한글 지원 폰트
sns.set(font='NanumGothic')
# 마이너스 부호
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.figsize'] = (15,10)
ax = sns.heatmap(matrix, xticklabels=genre_name, yticklabels=genre_name, annot=True, cmap='RdYlGn_r')
ax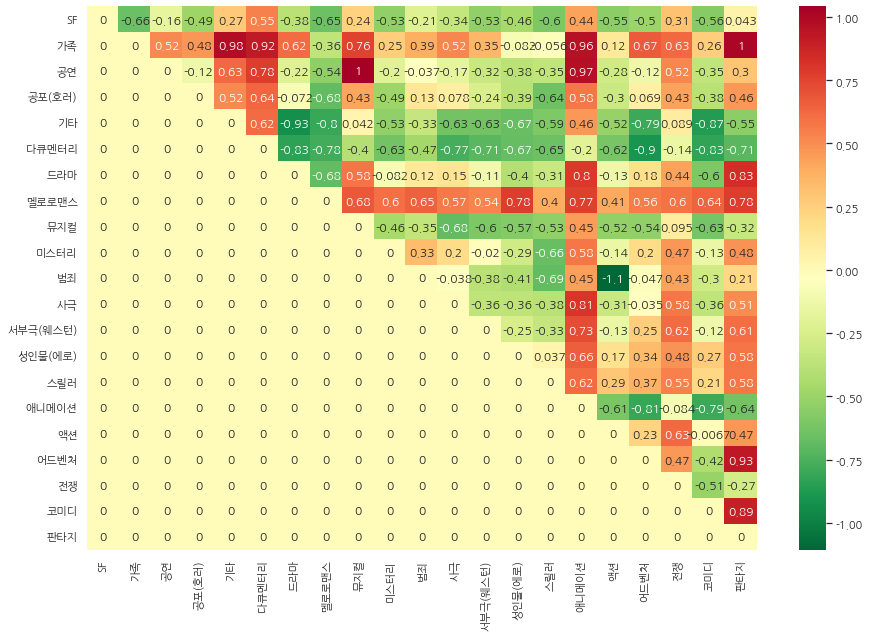
'AI > NLP Study' 카테고리의 다른 글
| [NLP] BM25를 이용한 영화 추천 (0) | 2023.01.07 |
|---|---|
| [NLP] 워드 임베딩 (1) | 2022.10.01 |
| [NLP] 텍스트 카테고리 분류 (1) | 2022.09.29 |
| [NLP] 텍스트 벡터화 (0) | 2022.09.27 |
| [NLP] 단어사전 만들기 (1) | 2022.09.25 |



